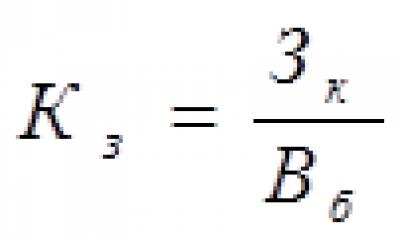
Полный вариант этой заметки (с формулами и таблицами) можно скачать с этой страницы в формате PDF. Размещенный на самой странице текст является кратким изложением содержания этой заметки и наиболее важных выводов.
Оптимистам от статистики посвящается
Коэффициент корреляции (КК) -- одна из наиболее простых и популярных статистик, характеризующих связь между случайными величинами. Одновременно КК удерживает первенство по числу сделанных с его помощью ошибочных и просто бессмысленных выводов. Такое положение обусловлено сложившейся практикой изложения материала, относящегося к корреляции и корреляционным зависимостям.
Большие, маленькие и "промежуточные" значения КК
При рассмотрении корреляционной связи подробно обсуждается понятие «сильной» (почти единичной) и «слабой» (почти нулевой) корреляции, но на практике ни та, ни другая никогда не встречаются. В результате остается неясным вопрос о разумной трактовке обычных для практики «промежуточных» значений КК. Коэффициент корреляции, равный 0.9 или 0.8 , новичку внушает оптимизм, а меньшие значения приводят его в замешательство.
По мере приобретения опыта оптимизм растет, и вот уже КК, равный 0.7 или 0.6 приводит исследователя в восторг, а оптимизм внушают значения 0.5 и 0.4 . Если же исследователь знаком с методами проверки статистических гипотез, то порог «хороших» значений КК падает до 0.3 или 0.2 .
Действительно, какие значения КК уже можно считать «достаточно большими», а какие остаются «слишком маленькими»? На этот вопрос имеется два диаметрально противоположных ответа -- оптимистичный и пессимистичный. Рассмотрим сначала оптимистичный (наиболее популярный) вариант ответа.
Значимость коэффициента корреляции
Этот вариант ответа дает нам классическая статистика и он связан с понятием статистической значимости КК. Мы рассмотрим здесь только ситуацию, когда интерес представляет положительная корреляционная связь (случай отрицательной корреляционной связи совершенно аналогичен). Более сложный случай, когда проверяется только наличие корреляционной связи без учета знака, относительно редко встречается на практике.
Если для КК r выполнено неравенство r > r e (n) , то говорят, что КК статистически значим при уровне значимости е . Здесь r e (n) -- квантиль, относительно которого нас будет интересовать только то, что при фиксированном уровне значимости e его значение стремится к нулю с ростом длины n выборки. Получается, что увеличивая массив данных можно добиться статистической значимости КК даже при весьма малых его значениях. В результате при наличии достаточно большой выборки появляется соблазн признать наличие в случае КК, равного, например, 0.06 . Тем не менее, здравый смысл подсказывает, что вывод о наличии значимой корреляционной связи при r=0.06 не может быть справедливым ни при каком объеме выборки. Остается понять природу ошибки. Для этого рассмотрим подробнее понятие статистической значимости.
Как обычно, при проверке статистических гипотез смысл проводимых расчетов кроется в выборе нуль-гипотезы и альтернативной гипотезы. При проверке значимости КК в качестве нуль-гипотезы берется предположение { r = 0 } при альтернативной гипотезе { r > 0 } (напомним, что мы рассматриваем здесь только ситуацию, когда интерес представляет положительная корреляционная связь). Выбираемый произвольно уровень значимости e определяет вероятность т.н. ошибки первого рода, когда нуль-гипотеза верна (r=0 ), но отклоняется статистическим критерием (т.е. критерий ошибочно признает наличие значимой корреляции). Выбирая уровень значимости, мы гарантируем малую вероятность такой ошибки, т.е. мы почти застрахованы от того, чтобы для независимых выборок (r=0 ) ошибочно признать наличие корреляционной связи (r > 0 ). Грубо говоря, значимость коэффициента корреляции означает только то, что он с большой вероятностью отличен от нуля .
Именно поэтому размер выборки и величина КК компенсируют друг друга -- большие выборки попросту позволяют добиться большей точности в локализации малого КК по его выборочной оценке.
Ясно, что понятие значимости не дает ответа на исходный вопрос о понимании категорий "большой/маленький" применительно к значениям КК. Ответ, даваемый критерием значимости, ничего не говорит нам о свойствах корреляционной связи, а позволяет только убедиться, что с большой вероятностью выполнено неравенство r > 0 . В то же время, само значение КК содержит значительно более существенную информацию о свойствах корреляционной связи. Действительно, одинаково значимые КК, равные 0.1 и 0.9 , существенно различаются по степени выраженности соответствующей корреляционной связи, а утверждение о значимости КК r = 0.06 для практики абсолютно бесполезно, поскольку при любых объемах выборки ни о какой корреляционной связи здесь говорить не приходится.
Окончательно можно сказать, что на практике из значимости коэффициента корреляции не следуют какие бы то ни было свойства корреляционной связи и даже само ее существование . С точки зрения практики порочен сам выбор альтернативной гипотезы, используемой при проверке значимости КК, поскольку случаи r=0 и r>0 при малых r с практической точки зрения неотличимы.
Фактически, когда из значимости КК выводят существование значимой корреляционной связи , производят совершенно беспардонную подмену понятий, основанную на смысловой неоднозначности слова "значимость". Значимость КК (четко определенное понятие) обманно превращают в "значимую корреляционную связь", а это словосочетание, не имеющее строгого определения, трактуют как синоним "выраженной корреляционной связи".
Расщепление дисперсии
Рассмотрим другой вариант ответа на вопрос о "малых" и "больших" значениях КК. Этот вариант ответа связан с выяснением регрессионоого смысла КК и оказывается весьма полезным для практики, хотя и отличается гораздо меньшим оптимизмом, чем критерии значимости КК.
Интересно, что обсуждение регрессионоого смысла КК часто наталкивается на трудности дидактического (а скорее психологического) характера. Кратко прокомментируем их. После формального введения КК и пояснения смысла "сильной" и "слабой" корреляционной связи считается необходимым углубиться в обсуждение философских вопросов соотношения между корреляционными и причинно-следственными связями. При этом делаются энергичные попытки откреститься от (гипотетической!) попытки трактовать корреляционную связь как причинно-следственную. На этом фоне обсуждение вопроса о наличии функциональной зависимости (в том числе и регрессионной) между коррелирующими величинами начинает казаться попросту кощунственной. Ведь от функциональной зависимости до причинно-следственной связи всего один шаг! В результате вопрос о регрессионном смысле КК вообще обходится стороной, так же как и вопрос о корреляционных свойствах линейной регресии.
На самом деле тут все просто. Если для нормированных (т.е. имеющих нулевое матожидание и единичную дисперсию) случайных величин X и Y имеет место соотношение
Y = a + bX + N,
где N -- некоторая случайная величина с нулевым матожиданием (аддитивный шум), то легко убедиться, что a = 0 и b = r . Это соотношение между случайными величинами X и Y называется уравнением линейной регрессии.
Вычисляя дисперсию случайной величины Y легко получить следующее выражение:
D[Y] = b 2 D[X] + D[N].
В последнем выражении первое слагаемое определяет вклад случайной величины X в дисперсию Y , а второе слагаемое -- вклад шума N в дисперсию Y . Используя полученное выше выражение для параметра b , легко выразить вклады случайных величин X и N через величину r = r (напомним, что мы считаем величины X и Y нормированными, т.е. D[X] = D[Y] = 1 ):
b 2 D[X] = r 2
D[N] = 1 - r 2
С учетом полученных формул часто говорят, что для случайных величин X и Y , связанных регрессионным уравнением, величина r 2 определяет долю дисперсии случайной величины Y , линейно обусловленную изменением случайной величины X . Итак, суммарная дисперсия случайной величины Y распадается на дисперсию, линейно обусловленную наличием регрессионной связи и остаточную дисперсию , обусловленную присутствием аддитивного шума.
Рассмотрим диаграмму рассеяния двумерной случайной величины (X, Y) . При малых D[N] диаграмма рассеяния вырождается в линейную зависимость между случайными величинами, слегка искаженную аддитивным шумом (т.е. точки на диаграмме рассеяния будут в основном сосредоточены вблизи прямой X=Y ). Такой случай имеет место при значениях r , близких по модулю к единице. При уменьшении (по модулю) величины КК дисперсия шумовой составляющей N начинает давать все больший вклад в дисперсию величины Y и при малых r диаграмма рассеяния полностью теряет сходство с прямой линией. В этом случае мы имеем облако точек, рассеяние которых в основном обусловлено шумом. Именно этот случай реализуется при значимых, но малых по абсолютной величине значениях КК. Ясно, что в этом случае ни о какой корреляционной связи говорить не приходится.
Посмотрим теперь, какой вариант ответа на вопрос о "больших" и "маленьких" значениях КК предлагает нам регрессионная интерпретация КК. В первую очередь необходимо подчеркнуть, что именно дисперсия является наиболее естественной мерой рассеяния значений случайной величины. Природа этой "естественности" состоит в аддитивности дисперсии для независимых случайных величин, но это свойство имеет очень многообразные проявления, к числу которых относится и продемонстрированное выше расщепление дисперсии на линейно обусловленную и остаточную дисперсии.
Итак, величина r 2 определяет долю дисперсии величины Y , линейно обусловленную наличием регрессионной связи со случайной величиной X . Вопрос о том, какую долю линейно обусловленной дисперсии можно считать признаком наличия выраженной корреляционной связи, остается на совести исследователя. Тем не менее, становится ясно, что малые значения коэффициента корреляции (r < 0.3 ) дают настолько малую долю линейно объясненной дисперсии, что бессмысленно говорить о какой бы то ни было выраженной корреляционной связи. При r > 0.5 можно говорить о наличии заметной корреляционной связи между величинами, а при r > 0.7 корреляционная связь может рассматриваться как существенная.
В научных исследованиях часто возникает необходимость в нахождении связи между результативными и факторными переменными (урожайностью какой-либо культуры и количеством осадков, ростом и весом человека в однородных группах по полу и возрасту, частотой пульса и температурой тела и т.д.).
Вторые представляют собой признаки, способствующие изменению таковых, связанных с ними (первыми).
Понятие о корреляционном анализе
Существует множество Исходя из вышеизложенного, можно сказать, что корреляционный анализ — это метод, применяющийся с целью проверки гипотезы о статистической значимости двух и более переменных, если исследователь их может измерять, но не изменять.
Есть и другие определения рассматриваемого понятия. Корреляционный анализ — это метод обработки заключающийся в изучении коэффициентов корреляции между переменными. При этом сравниваются коэффициенты корреляции между одной парой или множеством пар признаков, для установления между ними статистических взаимосвязей. Корреляционный анализ — это метод по изучению статистической зависимости между случайными величинами с необязательным наличием строгого функционального характера, при которой динамика одной случайной величины приводит к динамике математического ожидания другой.
Понятие о ложности корреляции
При проведении корреляционного анализа необходимо учитывать, что его можно провести по отношению к любой совокупности признаков, зачастую абсурдных по отношению друг к другу. Порой они не имеют никакой причинной связи друг с другом.
В этом случае говорят о ложной корреляции.
Задачи корреляционного анализа
Исходя из приведенных выше определений, можно сформулировать следующие задачи описываемого метода: получить информацию об одной из искомых переменных с помощью другой; определить тесноту связи между исследуемыми переменными.
Корреляционный анализ предполагает определение зависимости между изучаемыми признаками, в связи с чем задачи корреляционного анализа можно дополнить следующими:
- выявление факторов, оказывающих наибольшее влияние на результативный признак;
- выявление неизученных ранее причин связей;
- построение корреляционной модели с ее параметрическим анализом;
- исследование значимости параметров связи и их интервальная оценка.
Связь корреляционного анализа с регрессионным
Метод корреляционного анализа часто не ограничивается нахождением тесноты связи между исследуемыми величинами. Иногда он дополняется составлением уравнений регрессии, которые получают с помощью одноименного анализа, и представляющих собой описание корреляционной зависимости между результирующим и факторным (факторными) признаком (признаками). Этот метод в совокупности с рассматриваемым анализом составляет метод
Условия использования метода
Результативные факторы зависят от одного до нескольких факторов. Метод корреляционного анализа может применяться в том случае, если имеется большое количество наблюдений о величине результативных и факторных показателей (факторов), при этом исследуемые факторы должны быть количественными и отражаться в конкретных источниках. Первое может определяться нормальным законом — в этом случае результатом корреляционного анализа выступают коэффициенты корреляции Пирсона, либо, в случае, если признаки не подчиняются этому закону, используется коэффициент ранговой корреляции Спирмена.

Правила отбора факторов корреляционного анализа
При применении данного метода необходимо определиться с факторами, оказывающими влияние на результативные показатели. Их отбирают с учетом того, что между показателями должны присутствовать причинно-следственные связи. В случае создания многофакторной корреляционной модели отбирают те из них, которые оказывают существенное влияние на результирующий показатель, при этом взаимозависимые факторы с коэффициентом парной корреляции более 0,85 в корреляционную модель предпочтительно не включать, как и такие, у которых связь с результативным параметром носит непрямолинейный или функциональный характер.
Отображение результатов
Результаты корреляционного анализа могут быть представлены в текстовом и графическом видах. В первом случае они представляются как коэффициент корреляции, во втором — в виде диаграммы разброса.

При отсутствии корреляции между параметрами точки на диаграмме расположены хаотично, средняя степень связи характеризуется большей степенью упорядоченности и характеризуется более-менее равномерной удаленностью нанесенных отметок от медианы. Сильная связь стремится к прямой и при r=1 точечный график представляет собой ровную линию. Обратная корреляция отличается направленностью графика из левого верхнего в нижний правый, прямая — из нижнего левого в верхний правый угол.
Трехмерное представление диаграммы разброса (рассеивания)
Помимо традиционного 2D-представления диаграммы разброса в настоящее время используется 3D-отображение графического представления корреляционного анализа.

Также используется матрица диаграммы рассеивания, которая отображает все парные графики на одном рисунке в матричном формате. Для n переменных матрица содержит n строк и n столбцов. Диаграмма, расположенная на пересечении i-ой строки и j-ого столбца, представляет собой график переменных Xi по сравнению с Xj. Таким образом, каждая строка и столбец являются одним измерением, отдельная ячейка отображает диаграмму рассеивания двух измерений.

Оценка тесноты связи
Теснота корреляционной связи определяется по коэффициенту корреляции (r): сильная — r = ±0,7 до ±1, средняя — r = ±0,3 до ±0,699, слабая — r = 0 до ±0,299. Данная классификация не является строгой. На рисунке показана несколько иная схема.

Пример применения метода корреляционного анализа
В Великобритании было предпринято любопытное исследование. Оно посвящено связи курения с раком легких, и проводилось путем корреляционного анализа. Это наблюдение представлено ниже.
Профессиональная группа | смертность |
|
Фермеры, лесники и рыбаки | ||
Шахтеры и работники карьеров | ||
Производители газа, кокса и химических веществ | ||
Изготовители стекла и керамики | ||
Работники печей, кузнечных, литейных и прокатных станов | ||
Работники электротехники и электроники | ||
Инженерные и смежные профессии | ||
Деревообрабатывающие производства | ||
Кожевенники | ||
Текстильные рабочие | ||
Изготовители рабочей одежды | ||
Работники пищевой, питьевой и табачной промышленности | ||
Производители бумаги и печати | ||
Производители других продуктов | ||
Строители | ||
Художники и декораторы | ||
Водители стационарных двигателей, кранов и т. д. | ||
Рабочие, не включенные в другие места | ||
Работники транспорта и связи | ||
Складские рабочие, кладовщики, упаковщики и работники разливочных машин | ||
Канцелярские работники | ||
Продавцы | ||
Работники службы спорта и отдыха | ||
Администраторы и менеджеры | ||
Профессионалы, технические работники и художники |
Начинаем корреляционный анализ. Решение лучше начинать для наглядности с графического метода, для чего построим диаграмму рассеивания (разброса).

Она демонстрирует прямую связь. Однако на основании только графического метода сделать однозначный вывод сложно. Поэтому продолжим выполнять корреляционный анализ. Пример расчета коэффициента корреляции представлен ниже.
С помощью программных средств (на примере MS Excel будет описано далее) определяем коэффициент корреляции, который составляет 0,716, что означает сильную связь между исследуемыми параметрами. Определим статистическую достоверность полученного значения по соответствующей таблице, для чего нам нужно вычесть из 25 пар значений 2, в результате чего получим 23 и по этой строке в таблице найдем r критическое для p=0,01 (поскольку это медицинские данные, здесь используется более строгая зависимость, в остальных случаях достаточно p=0,05), которое составляет 0,51 для данного корреляционного анализа. Пример продемонстрировал, что r расчетное больше r критического, значение коэффициента корреляции считается статистически достоверным.
Использование ПО при проведении корреляционного анализа
Описываемый вид статистической обработки данных может осуществляться с помощью программного обеспечения, в частности, MS Excel. Корреляционный предполагает вычисление следующих парамет-ров с использованием функций:
1. Коэффициент корреляции определяется с помощью функции КОРРЕЛ (массив1; массив2). Массив1,2 — ячейка интервала значений результативных и факторных переменных.
Линейный коэффициент корреляции также называется коэффициентом корреляции Пирсона, в связи с чем, начиная с Excel 2007, можно использовать функцию с теми же массивами.
Графическое отображение корреляционного анализа в Excel производится с помощью панели «Диаграммы» с выбором «Точечная диаграмма».
После указания исходных данных получаем график.
2. Оценка значимости коэффициента парной корреляции с использованием t-критерия Стьюдента. Рассчитанное значение t-критерия сравнивается с табличной (критической) величиной данного показателя из соответствующей таблицы значений рассматриваемого параметра с учетом заданного уровня значимости и числа степеней свободы. Эта оценка осуществляется с использованием функции СТЬЮДРАСПОБР (вероятность; степени_свободы).
3. Матрица коэффициентов парной корреляции. Анализ осуществляется с помощью средства «Анализ данных», в котором выбирается «Корреляция». Статистическую оценку коэффициентов парной корреляции осуществляют при сравнении его абсолютной величины с табличным (критическим) значением. При превышении расчетного коэффициента парной корреляции над таковым критическим можно говорить, с учетом заданной степени вероятности, что нулевая гипотеза о значимости линейной связи не отвергается.
В заключение
Использование в научных исследованиях метода корреляционного анализа позволяет определить связь между различными факторами и результативными показателями. При этом необходимо учитывать, что высокий коэффициент корреляции можно получить и из абсурдной пары или множества данных, в связи с чем данный вид анализа нужно осуществлять на достаточно большом массиве данных.
После получения расчетного значения r его желательно сравнить с r критическим для подтверждения статистической достоверности определенной величины. Корреляционный анализ может осуществляться вручную с использованием формул, либо с помощью программных средств, в частности MS Excel. Здесь же можно построить диаграмму разброса (рассеивания) с целью наглядного представления о связи между изучаемыми факторами корреляционного анализа и результативным признаком.
Значимость коэффициентов корреляции проверяемся по критерию Стьюдента:
где - среднеквадратическая ошибка коэффициента корреляции, которая определяется по формуле:
Если расчетное значение (выше табличного, то можно сделать заключение о том, что величина коэффициента корреляции является значимой. Табличные значения t находят по таблице значений критериев Стьюдента. При этом учитываются количество степеней свободы (V = п - 1)и уровень доверительной вероятности (в экономических расчетах обычно 0,05 или 0,01). В нашем примере количество степеней свободы равно: п - 1 = 40 - 1 = 39. При уровне доверительной вероятности Р = 0,05; t = 2,02. Поскольку (фактическое (табл. 7.8) во всех случаях выше t-табличного, связь между результативным и факторными показателями является надежной, а величина коэффициентов корреляции - значимой.

Следующий этап корреляционного анализа -расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, F-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны.
Сравнивая результаты на каждом шаге (табл.7.9), мы можем сделать вывод, что наиболее полно описывает зависимости между изучаемыми показателями пятифакторная модель, полученная на пятом шаге. В результате уравнение связи имеет вид:

Коэффициенты уравнения показывают количественное воздействие каждого фактора на результативный показатель при неизменности других. В данном случае можно дать следующую интерпретацию полученному уравнению: рентабельность повышается на 3,65 % при увеличении материалоотдачи на 1 руб.; на 0,09 % - с ростом фондоотдачи на 1 коп.; на 1,02 %-с повышением среднегодовой выработки продукции на одного работника на 1 млн руб.; на 0,052 %- при увеличении удельного веса продукции высшей категории качества на 1 %. С увеличением продолжительности оборота средств на 1 день рентабельность снижается в среднем на 0,122 %.
Коэффициенты регрессии в уравнении связи имеют разные единицы измерения, что делает их несопоставимыми, если возникает вопрос о сравнительной силе воздействия факторов на результативный показатель. Чтобы привести их в сопоставимый вид, все переменные уравнения регрессии выражают в долях среднеквадратического отклонения, другими словами, рассчитывают стандартизированные коэффициенты регрессии. Их еще называют бетта-коэффициентами по символу, который принят для их обозначения (р).
Бетта-коэффициенты и коэффициенты регрессии связаны следующим отношением:
Смотрите также:
Этап 3. Нахождение взаимосвязи между данными
Линейная корреляция
Последний этап задачи изучения связей между явлениями – оценка тесноты связи по показателям корреляционной связи. Этот этап очень важен для выявления зависимостей между факторными и результативными признаками, а следовательно, для возможности осуществления диагноза и прогноза изучаемого явления.
Диагноз (от греч. diagnosis распознавание) – определение существа и особенностей состояния какого-либо объекта или явления на основе его всестороннего исследования.
Прогноз (от греч. prognosis предвидение, предсказание) – всякое конкретное предсказание, суждение о состоянии какого-либо явления в будущем (прогноз погоды, исхода выборов и т.п.). Прогноз – это научно обоснованная гипотеза о вероятном будущем состоянии изучаемой системы, объекта или явления и характеризующие это состояние показатели. Прогнозирование – разработка прогноза, специальные научные исследования конкретных перспектив развития какого-либо явления.
Вспомним определение корреляции:
Корреляция – зависимость между случайными величинами, выражающаяся в том, что распределение одной величины зависит от значения другой величины.
Корреляционная связь наблюдается не только между количественными, но и качественными признаками. Существуют различные способы и показатели оценки тесноты связей. Мы остановимся лишь на линейном коэффициенте парной корреляции , который используется при наличии линейной связи между случайными величинами. На практике часто возникает необходимость определить уровень связи между случайными величинами неодинаковой размерности, поэтому желательно располагать какой-то безразмерной характеристикой этой связи. Такой характеристикой (мерой связи) является коэффициент линейной корреляции r xy , который определяется по формуле
где  ,
,  .
.
Обозначив и , можно получить следующее выражение для расчета коэффициента корреляции
 .
.
Если ввести понятие нормированного отклонения , которое выражает отклонение коррелируемых значений от среднего в долях среднего квадратического отклонения:
то выражение для коэффициента корреляции примет вид
![]() .
.
Если производить расчет коэффициента корреляции по итоговым значениям исходных случайных величин из расчетной таблицы, то коэффициент корреляции можно вычислить по формуле
 .
.
Свойства коэффициента линейной корреляции:
1). Коэффициент корреляции – безразмерная величина.
2). |r | £ 1 или .
3). , a,b = const, – величина коэффициента корреляции не изменится, если все значения случайных величин X и Y умножить (или разделить) на константу.
4). , a,b = const, – величина коэффициента корреляции не изменится, если все значения случайных величин X и Y увеличить (или уменьшить) на константу.
5). Между коэффициентом корреляции и коэффициентом регрессии существует связь:
Интерпретировать значения коэффициентов корреляции можно следующим образом:
Количественные критерии оценки тесноты связи:
В прогностических целях обычно используют величины с |r| > 0.7.
Коэффициент корреляции позволяет сделать вывод о существовании линейной зависимости между двумя случайными величинами, но не указывает, какая из величин обуславливает изменение другой. В действительности связь между двумя случайными величинами может существовать и без причинно-следственной связи между самими величинами, т.к. изменение обеих случайных величин может быть вызвано изменением (влиянием) третьей.
Коэффициент корреляции r xy является симметричным по отношению к рассматриваемым случайным величинам X и Y . Это означает, что для определения коэффициента корреляции совершенно безразлично, какая из величин является независимой, а какая – зависимой.
Значимость коэффициента корреляции
Даже для независимых величин коэффициент корреляции может оказаться отличным от нуля вследствие случайного рассеяния результатов измерений или вследствие небольшой выборки случайных величин. Поэтому следует проверять значимость коэффициента корреляции.
Значимость линейного коэффициента корреляции проверяется на основе t-критерия Стьюдента :
 .
.
Если t > t кр (P, n -2), то линейный коэффициент корреляции значим, а следовательно, значима и статистическая связь X и Y .
 .
.
Для удобства вычислений созданы таблицы значений доверительных границ коэффициентов корреляции для различного числа степеней свободы f = n –2 (двусторонний критерий) и различных уровней значимости a = 0,1; 0,05; 0,01 и 0,001. Считается, что корреляция значима, если рассчитанный коэффициент корреляции превосходит значение доверительной границы коэффициента корреляции для заданных f и a .
Для больших n и a = 0,01 значение доверительной границы коэффициента корреляции можно вычислить по приближенной формуле
![]() .
.
Как неоднократно отмечалось, для статистического вывода о наличии или отсутствии корреляционной связи между исследуемыми переменными необходимо произвести проверку значимости выборочного коэффициента корреляции. В связи с тем что надежность статистических характеристик, в том числе и коэффициента корреляции, зависит от объема выборки, может сложиться такая ситуация, когда величина коэффициента корреляции будет целиком обусловлена случайными колебаниями в выборке, на основании которой он вычислен. При существенной связи между переменными коэффициент корреляции должен значимо отличаться от нуля. Если корреляционная связь между исследуемыми переменными отсутствует, то коэффициент корреляции генеральной совокупности ρ равен нулю. При практических исследованиях, как правило, основываются на выборочных наблюдениях. Как всякая статистическая характеристика, выборочный коэффициент корреляции является случайной величиной, т. е. его значения случайно рассеиваются вокруг одноименного параметра генеральной совокупности (истинного значения коэффициента корреляции). При отсутствии корреляционной связи между переменными у и х коэффициент корреляции в генеральной совокупности равен нулю. Но из-за случайного характера рассеяния принципиально возможны ситуации, когда некоторые коэффициенты корреляции, вычисленные по выборкам из этой совокупности, будут отличны от нуля.
Могут ли обнаруженные различия быть приписаны случайным колебаниям в выборке или они отражают существенное изменение условий формирования отношений между переменными? Если значения выборочного коэффициента корреляции попадают в зону рассеяния, обусловленную случайным характером самого показателя, то это не является доказательством отсутствия связи. Самое большее, что при этом можно утверждать, сводится к тому, что данные наблюдений не отрицают отсутствия связи между переменными. Но если значение выборочного коэффициента корреляции будет лежать вне упомянутой зоны рассеяния, то делают вывод, что он значимо отличается от нуля, и можно считать, что между переменными у и х существует статистически значимая связь. Используемый для решения этой задачи критерий, основанный на распределении различных статистик, называется критерием значимости.
Процедура проверки значимости начинается с формулировки нулевой гипотезы H 0 . В общем виде она заключается в том, что между параметром выборки и параметром генеральной совокупности нет каких- либо существенных различий. Альтернативная гипотеза H 1 состоит в том, что между этими параметрами имеются существенные различия. Например, при проверке наличия корреляции в генеральной совокупности нулевая гипотеза заключается в том, что истинный коэффициент корреляции равен нулю (Н0 : ρ = 0). Если в результате проверки окажется, что нулевая гипотеза не приемлема, то выборочный коэффициент корреляции r ух значимо отличается от нуля (нулевая гипотеза отвергается и принимается альтернативная Н1). Другими словами, предположение о некоррелированности случайных переменных в генеральной совокупности следует признать необоснованным. И наоборот, если на основе критерия значимости нулевая гипотеза принимается, т. е. r ух лежит в допустимой зоне случайного рассеяния, то нет оснований считать сомнительным предположение о некоррелированности переменных в генеральной совокупности.
При проверке значимости исследователь устанавливает уровень значимости α, который дает определенную практическую уверенность в том, что ошибочные заключения будут сделаны только в очень редких случаях. Уровень значимости выражает вероятность того, что нулевая гипотеза Н0 отвергается в то время, когда она в действительности верна. Ясно, что имеет смысл выбирать эту вероятность как можно меньшей.
Пусть известно распределение выборочной характеристики, являющейся несмещенной оценкой параметра генеральной совокупности. Выбранному уровню значимости α соответствуют под кривой этого распределения заштрихованные площади (см. рис. 24). Незаштрихованная площадь под кривой распределения определяет вероятность Р = 1 - α. Границы отрезков на оси абсцисс под заштрихованными площадями называют критическими значениями, а сами отрезки образуют критическую область, или область отклонения гипотезы.
При процедуре проверки гипотезы выборочную характеристику, вычисленную по результатам наблюдений, сравнивают с соответствующим критическим значением. При этом следует различать одностороннюю и двустороннюю критические области. Форма задания критической области зависит от постановки задачи при статистическом исследовании. Двусторонняя критическая область необходима в том случае, когда при сравнении параметра выборки и параметра генеральной совокупности требуется оценить абсолютную величину расхождения между ними, т. е. представляют интерес как положительные, так и отрицательные разности между изучаемыми величинами. Когда же надо убедиться в том, что одна величина в среднем строго больше или меньше другой, используется односторонняя критическая область (право- или левосторонняя). Вполне очевидно, что для одного и того же критического значения уровень значимости при использовании односторонней критической области меньше, чем при использовании двусторонней. Если распределение выборочной характеристики симметрично,
Рис. 24. Проверка нулевой гипотезы H0
то уровень значимости двусторонней критической области равен α, а односторонней - (см. рис. 24). Ограничимся лишь общей постановкой проблемы. Более подробно с теоретическим обоснованием проверки статистических гипотез можно познакомиться в специальной литературе. Далее мы лишь укажем критерии значимости для различных процедур, не останавливаясь на их построении.
Проверяя значимость коэффициента парной корреляции, устанавливают наличие или отсутствие корреляционной связи между исследуемыми явлениями. При отсутствии связи коэффициент корреляции генеральной совокупности равен нулю (ρ = 0). Процедура проверки начинается с формулировки нулевой и альтернативной гипотез:
Н0 : различие между выборочным коэффициентом корреляцииr и ρ = 0 незначимо,
Н1 : различие междуr и ρ = 0 значимо, и следовательно, между переменнымиу и х имеется существенная связь. Из альтернативной гипотезы следует, что нужно воспользоваться двусторонней критической областью.
В разделе 8.1 уже упоминалось, что выборочный коэффициент корреляции при определенных предпосылках связан со случайной величиной t , подчиняющейся распределению Стьюдента сf = п - 2 степенями свободы. Вычисленная по результатам выборки статистика
сравнивается с критическим значением, определяемым по таблице распределения Стьюдента при заданном уровне значимости α и f = п - 2 степенях свободы. Правило применения критерия заключается в следующем: если |t | >tf ,а , то нулевая гипотеза на уровне значимостиα отвергается, т. е. связь между переменными значима; если |t | ≤tf ,а , то нулевая гипотеза на уровне значимостиαпринимается. Отклонение значенияr от ρ = 0 можно приписать случайной вариации. Данные выборки характеризуют рассматриваемую гипотезу как весьма возможную и правдоподобную, т. е. гипотеза об отсутствии связи не вызывает возражений.
Процедура проверки гипотезы значительно упрощается, если вместо статистики t воспользоваться критическими значениями коэффициента корреляции, которые могут быть определены через квантили распределения Стьюдента путем подстановки в (8.38)t = tf , а иr = ρ f , а:
![]() (8.39)
(8.39)
Существуют подробные таблицы критических значений, выдержка из которых приведена в приложении к данной книге (см. табл. 6). Правило проверки гипотезы в этом случае сводится к следующему: если r > ρ f , а, то можем утверждать, что связь между переменными существенная. Еслиr ≤rf ,а , то результаты наблюдений считаем непротиворечащими гипотезе об отсутствии связи.
Трудовые отношения

Должностная инструкция главного инженера, должностные обязанности главного инженера, образец должностной инструкции главного инженера Должностная инструкция главного инженера рэс
Открытие бизнеса

Где можно и где нельзя работать после туберкулеза Где можно работать после
Форекс