
Рассмотрим вначале коэффициент детерминации для простой линейной регрессии, называемый также коэффициентом парной детерминации.
На основе соображений, изложенных в разделе 3.1, теперь относительно легко найти меру точности оценки регрессии. Мы показали, что общую дисперсию можно разложить на две составляющие - на «необъясненную» дисперсию и дисперсию обусловленную регрессией. Чем больше по сравнению с тем больше общая дисперсия формируется за счет влияния объясняющей переменной х и, следовательно, связь между двумя переменными у их более интенсивная. Очевидно, удобно в качестве показателя интенсивности связи, или оценки доли влияния переменной х на использовать отношение

Это отношение указывает, какая часть общего (полного) рассеяния значений у обусловлена изменчивостью переменной х. Чем большую долю в общей дисперсии составляет тем лучше выбранная функция регрессии соответствует эмпирическим данным. Чем меньше эмпирические значения зависимой переменной отклоняются от прямой регрессии, тем лучше определена функция регрессии. Отсюда происходит и название отношения (3.6) - коэффициент детерминации Индекс при коэффициенте указывает на переменные, связь между которыми изучается. При этом вначале в индексе стоит обозначение зависимой переменной, а затем объясняющей.
Из определения коэффициента детерминации как относительной доли очевидно, что он всегда заключен в пределах от 0 до 1:
![]()
Если то все эмпирические значения (все точки поля корреляции) лежат на регрессионной прямой. Это означает, что для В этом случае говорят о строгом линейном соотношении (линейной функции) между переменными у их. Если дисперсия, обусловленная регрессией, равна нулю, а
«необъясненная» дисперсия равна общей дисперсии. В этом случае Линия регрессии тогда параллельна оси абсцисс. Ни о какой численной линейной зависимости переменной у от в статистическом ее понимании не может быть и речи. Коэффициент регрессии при этом незначимо отличается от нуля.
Итак, чем больше приближается к единице, тем лучше определена регрессия.
Коэффициент детерминации есть величина безразмерная и поэтому он не зависит от изменения единиц измерения переменных у и х (в отличие от параметров регрессии). Коэффициент не реагирует на преобразование переменных.
Приведем некоторые модификации формулы (3.6), которые, с одной стороны, будут способствовать пониманию сущности коэффициента детерминации, а с другой стороны, окажутся полезными для практических вычислений. Подставляя выражение для в (3.6) и принимая во внимание (1.8) и (3.1), получим:
![]()
Эта формула еще раз подтверждает, что «объясненная» дисперсия, стоящая в числителе (3.6), пропорциональна дисперсии переменной х, так как является оценкой параметра регрессии.
Подставив вместо его выражение (2.26) и учитывая определения дисперсий а также средних х и у, получим формулу коэффициента детерминации, удобную для вычисления:


Из (3.9) следует, что всегда С помощью (3.9) можно относительно легко определить коэффициент детерминации. В этой формуле содержатся только те величины, которые используются для вычисления оценок параметров регрессии и, следовательно, имеются в рабочей таблице. Формула (3.9) обладает тем преимуществом, что вычисление коэффициента детерминации по ней производится непосредственно по эмпирическим данным. Не нужно заранее находить оценки параметров и значения регрессии. Это обстоятельство играет немаловажную роль для последующих исследований, так как перед проведением регрессионного анализа мы можем проверить, в какой степени определена исследуемая регрессия включенными в нее объясняющими
переменными. Если коэффициент детерминации слишком мал, то нужно искать другие факторы-переменные, причинно обусловливающие зависимую переменную. Следует отметить, что коэффициент детерминации удовлетворительно отвечает своему назначению при достаточно большом числе наблюдений. Но в любом случае необходимо проверить значимость коэффициента детерминации. Эта проблема будет обсуждаться в разделе 8.6.
Вернемся к рассмотрению «необъясненной» дисперсии, возникающей за счет изменчивости прочих факторов-переменных, не зависящих от х, а также за счет случайностей. Чем больше ее доля в общей дисперсии, тем меньше, неопределеннее проявляется соотношение между у и х, тем больше затушевывается связь между ними. Исходя из этих соображений мы можем использовать «необъясненную» дисперсию для характеристики неопределенности или неточности регрессии. Следующее соотношение служит мерой неопределенности регрессии:

Легко убедиться в том, что
![]()
![]()
Отсюда очевидно, что не нужно отдельно вычислять меру неопределенности, а ее оценку легко получить из (3.11).
Теперь вернемся к нашим примерам и определим коэффициенты детерминации для полученных уравнений регрессий.
Вычислим коэффициент детерминации по данным примера из раздела 2.4 (зависимость производительности труда от уровня механизации работ). Используем для этого формулу (3.9), а промежуточные результаты вычислений заимствуем из табл. 3:
Отсюда заключаем, что в случае простой регрессии 93,8% общей дисперсии производительности труда на рассматриваемых предприятиях обусловлено вариацией показателя механизации работ. Таким образом, изменчивость переменной х почти полностью объясняет вариацию переменной у.
Для этого примера коэффициент неопределенности т. е. только 6,2% общей дисперсии нельзя объяснить зависимостью производительности труда от уровня механизации работ.
Вычислим коэффициент детерминации по данным примера из раздела 2.5 (зависимость объема производства от основных фондов). Необходимые
промежуточные результаты вычислений приведены в разделе 2.5 при определении оценок коэффициентов регрессии:
Таким образом, 91,1% общей дисперсии объема производства исследуемых предприятий обусловлено изменчивостью значений основных фондов на этих предприятиях. Данная регрессия почти полностью исчерпывается включенной в нее объясняющей переменной. Коэффициент неопределенности составляет 0,089, или 8,9%.
Следует отметить, что приведенные в данном разделе формулы предназначены для вычисления по результатам выборки большого объема коэффициента детерминации в случае простой регрессии. Но чаще всего приходится довольствоваться выборкой небольшого объема . В этом случае вычисляют исправленный коэффициент детерминации учитывая соответствующее число степеней свободы. Формула исправленного коэффициента детерминации для общего случая объясняющих переменных будет приведена в следующем разделе. Из нее легко получить формулу исправленного коэффициента детерминации в случае простой регрессии
Коэффициент множественной детерминации характеризует, на сколько процентов построенная модель регрессии объясняет вариацию значений результативной переменной относительно своего среднего уровня, т. е. показывает долю общей дисперсии результативной переменной, объяснённой вариацией факторных переменных, включённых в модель регрессии.
Коэффициент множественной детерминации также называется количественной характеристикой объяснённой построенной моделью регрессии дисперсии результативной переменной. Чем больше значение коэффициента множественной детерминации, тем лучше построенная модель регрессии характеризует взаимосвязь между переменными.
Для коэффициента множественной детерминации всегда выполняется неравенство вида:
Следовательно, включение в линейную модель регрессии дополнительной факторной переменной xn не снижает значения коэффициента множественной детерминации.
Коэффициент множественной детерминации может быть определён не только как квадрат множественного коэффициента корреляции, но и с помощью теоремы о разложении сумм квадратов по формуле:

где ESS (Error Sum Square) – сумма квадратов остатков модели множественной регрессии с n независимыми переменными:
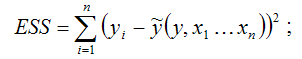
TSS (TotalSumSquare) – общая сумма квадратов модели множественной регрессии с n независимыми переменными:

Однако классический коэффициент множественной детерминации не всегда способен определить влияние на качество модели регрессии дополнительной факторной переменной. Поэтому наряду с обычным коэффициентом рассчитывают также и скорректированный (adjusted) коэффициент множественной детерминации, в котором учитывается количество факторных переменных, включённых в модель регрессии:

где n – количество наблюдений в выборочной совокупности;
h – число параметров, включённых в модель регрессии.
При большом объёме выборочной совокупности значения обычного и скорректированного коэффициентов множественной детерминации отличаться практически не будут.
24. Парный регрессионный анализ
Одним из методов изучения стохастических связей между признаками является регрессионный анализ.
Регрессионный анализ представляет собой вывод уравнения регрессии, с помощью которого находится средняя величина случайной переменной (признака-результата), если величина другой (или других) переменных (признаков-факторов) известна. Он включает следующие этапы:
выбор формы связи (вида аналитического уравнения регрессии);
оценку параметров уравнения;
оценку качества аналитического уравнения регрессии.
Наиболее часто для описания статистической связи признаков используется линейная форма. Внимание к линейной связи объясняется четкой экономической интерпретацией ее параметров, ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связи для выполнения расчетов преобразуют (путем логарифмирования или замены переменных) в линейную форму.
В случае линейной парной связи уравнение регрессии примет вид:
Параметры данного
уравнения а и b оцениваются по данным
статистического наблюдения x и y.
Результатом такой оценки является
уравнение:
![]() , где,- оценки параметров
a и b,
- значение
результативного признака (переменной),
полученное по уравнению регрессии
(расчетное значение).
, где,- оценки параметров
a и b,
- значение
результативного признака (переменной),
полученное по уравнению регрессии
(расчетное значение).
Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и несмещенные) оценки параметров уравнения регрессии. Но только в том случае, если выполняются определенные предпосылки относительно случайного члена (u) и независимой переменной (x).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов состоит в следующем:
получить такие оценки параметров ,, при которых сумма квадратов отклонений фактических значений результативного признака - yi от расчетных значений – минимальна.
Формально критерий МНК можно записать так:
![]()
Проиллюстрируем суть данного метода графически. Для этого построим точечный график по данным наблюдений (xi ,yi, i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.

Математическая запись данной задачи:
![]()
Значения yi и xi i=1; n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров - ,. Чтобы найти минимум функции 2-ух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е.
![]()
В результате получим систему из 2-ух нормальных линейных уравнений:

Решая данную систему, найдем искомые оценки параметров:

Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм
(возможно некоторое расхождение из-за округления расчетов).
Знак коэффициента регрессии b указывает направление связи (если b>0, связь прямая, если b <0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значение параметра а – среднее значение y при х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра а не имеет смысла.
Оценка тесноты связи между признаками осуществляется с помощью коэффициента линейной парной корреляции - rx,y. Он может быть рассчитан по формуле:

Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
Область допустимых значений линейного коэффициента парной корреляции от –1 до +1. Знак коэффициента корреляции указывает направление связи. Если rx, y>0, то связь прямая; если rx, y<0, то связь обратная.
Если данный коэффициент по модулю близок к единице, то связь между признаками может быть интерпретирована как довольно тесная линейная. Если его модуль равен единице ê rx , y ê =1, то связь между признаками функциональная линейная. Если признаки х и y линейно независимы, то rx,y близок к 0.
Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R2yx:

где d 2 – объясненная уравнением регрессии дисперсия y;
e 2- остаточная (необъясненная уравнением регрессии) дисперсия y;
s 2 y - общая (полная) дисперсия y .
Коэффициент детерминации характеризует долю вариации (дисперсии) результативного признака y, объясняемую регрессией (а, следовательно, и фактором х), в общей вариации (дисперсии) y. Коэффициент детерминации R2yx принимает значения от 0 до 1. Соответственно величина 1-R2yx характеризует долю дисперсии y, вызванную влиянием прочих неучтенных в модели факторов и ошибками спецификации.
При парной линейной регрессии R 2yx=r2 yx.
Предположим, что экономические предпосылки и анализ расположения точек на корреляционном поле позволил нам выдвинуть гипотезу о том, что зависимость результирующего признака у от фактора х может быть описана следующей моделью:
Причем, как не раз мы уже отмечали коэффициенты 0 и 1 в этом уравнении неизвестны. Используя МНК, мы можем найти оценки этих коэффициентов в 0 и в 1 и записать следующее выражение для у:
На приведенном рисунке (Рис.4) изображены фактические значения переменной у, график гипотетической функции регрессии (которая, вообще говоря, нам неизвестна!) и график эмпирической функции регрессии, коэффициенты которой найдены из условия минимума суммы квадратов ошибок.
Рис.4.
Исходя из логики наших действий, возникают два вопроса:
- ?Можно ли с той или иной вероятностью найти подтверждение, что вид функциональной зависимости (речь пока идет только о линейной функции) выбран корректно.
- ?Насколько хорошо, со статистической точки зрения, оценки неизвестных параметров, полученные по МНК, приближают неизвестные коэффициенты.
Для ответов на поставленные вопросы нам понадобится, в частности, понятие коэффициента детерминации. Перед тем как ввести это понятие рассмотрим следующую сумму:
Покажем, что ее можно представить в виде:


Действительно,

Через обозначена функция регрессии, полученная по МНК: .
Покажем, что последнее слагаемое в (1) равно нулю, для этого запишем его в виде:



Рассмотрим слагаемое


В силу равенства (2), можно утверждать, что оно равно 0. Преобразуем теперь первое слагаемое:




Оба слагаемых равны нулю в силу равенств (2) и (3).
Таким образом, мы показали, что имеет место, следующее представление для рассматриваемой суммы:

Величину е i равную:
будем называть остатком. Следовательно, первое слагаемое в правой части (2) есть сумма квадратов остатков:

Ее называют остаточной суммой квадратов и обозначают RSS (residual sum of squares).
Вторая сумма это сумма квадратов отклонений точек, расположенных на регрессионной прямой от прямой у =. Эту сумму называют суммой квадратов отклонений, объясненной регрессией ЕSS (explained sum of squares).
В левой части равенства (2) находится сумма квадратов отклонений фактических значений переменной у от прямой у =. Такую сумму называют полной суммой квадратов и обозначают TSS (total sum of squares).
Таким образом, полная сумма квадратов TSS разбилась на две составляющие:
TSS= RSS+ ESS. (3)
- ? ESS- сумму квадратов, обусловленных влиянием основного фактора х;
- ? RSS - сумму квадратов, обусловленных влиянием других, в том числе и случайных факторов.
Замечание 1. Следует иметь в виду, что в литературе по эконометрике, в частности в , эту же систему обозначений используют с точностью до наоборот, давая ей другое объяснение. Сумму, которая выше обозначена как ЕSS обозначают через RSS и расшифровывают так: regression sum of squares. И наоборот, сумму, обозначенную нами как RSS называют ЕSS: error sum of squares. Мы будем придерживаться введенной выше терминологии. ^
Замечание 2.Рассмотрим два частных случая. Предположим, что x не оказывает никакого влияния на y, тогда выборочное условное среднее совпадает с выборочным средним, в такой ситуации ЕSS =0 и
В том случае, когда на зависимую переменную у не оказывает влияния никакие другие факторы, кроме х, сумма RSS будет равняться нулю и будет выполняться следующее равенство:
В общем же случае, если оценки параметров функции регрессии найдены по МНК, всегда будет иметь место равенство (3).^
Определение 1. Парным коэффициентом детерминации (выборочным) называют отношение:
Говорят, что «коэффициент детерминации показывает, какая доля дисперсии величины y определяется (детерминируется) изменчивостью (дисперсией) соответствующей функции регрессии y от x» .
Поясним сказанное. Для этого вернемся к равенству (2) и разделим обе части равенства на n, получим:


Тогда выражение для парного коэффициента детерминации можно представить в виде:
Следует отметить, что введенный нами парный коэффициент детерминации также относится к выборочным числовым характеристикам и рассчитывается по эмпирическим данным. Теоретический коэффициент детерминации будем обозначать R xy .
Рассмотрим, в каком диапазоне изменяется значение коэффициента детерминации. Очевидно, что эта величина всегда неотрицательна. Найдем верхнюю границу. Из равенства (3) следует следующее равенство:
Следовательно,
Отсюда очевидно, что в силу того, что наименьшее значение RSS =0, наибольшее значение коэффициента детерминации равно 1. Таким образом,
Отметим, что значение коэффициента детерминации тем ближе к 1, чем меньше остаточная сумма квадратов. В этом случае говорят, что уравнение регрессии статистически значимо и фактор х оказывает сильное воздействие на результирующий признак у (последний тезис справедлив только для модели парной линейной регрессии!).
Покажем, как связаны коэффициент парной детерминации с выборочным коэффициентом корреляции, чтобы аргументировать последнее утверждение.

Подставим это выражение в числитель формулы (5):

Следовательно, в случае парной линейной регрессии, коэффициент детерминации равен квадрату выборочного коэффициента корреляции:
Замечание 1. Из теории вероятностей известно следующее свойство коэффициента корреляции. Коэффициент корреляции двух случайных величин равен 1 или -1 тогда и только тогда, когда случайные величины связаны между собой линейно, т.е. у = ах + в. Классификация силы связи двух случайных величин в зависимости от величины коэффициента корреляции (теоретического!) может производиться следующим образом.
Если то связь между случайными величинами классифицируют как слабую; если то силу связи между двумя случайными величинами классифицируют как среднюю и, наконец, если, то говорят, что имеет место сильная стохастическая зависимость. Причем, если коэффициент корреляции положительный, то связь классифицируют как прямую, то есть значение обеих случайных величин увеличиваются, или уменьшаются одновременно. Отрицательное значение коэффициента корреляции говорит об обратной связи, то есть, например, увеличение значений одной случайной величины ведет к уменьшению значений другой. Следует иметь в виду, что использование выборочного коэффициента корреляции для подобной классификации, требует вдумчивого подхода. Эта характеристика является по своей сути случайной величиной и нельзя по ее значению делать категоричные выводы, подобные тем, которые производят, ориентируясь на. Все суждения, должны носить уже в этом случае более осторожный характер.
Тем не менее, и выборочный коэффициент корреляции и парный коэффициент детерминации служат хорошим индикатором, позволяющим нам делать предположение о том, что зависимость между х и у имеет место, и она носит вид линейной функциональной зависимости.
Вернемся к парному коэффициенту детерминации. Если модуль выборочного коэффициента корреляции близок к 1, то из формулы (6) следует, что близок к 1 и. Таким образом, близость коэффициента детерминации или абсолютной величины выборочного коэффициента корреляции к 1, служит ещё одним основанием в поддержку предположения, что функция регрессии линейна.
При анализе модели парной линейной регрессии будем делать следующие предварительные выводы о качестве модели.
- ?Если , то будем считать, что использование регрессионной модели для аппроксимации зависимости между у и х статистически необоснованно.
- ?Если (0,09; 0,49], то использование регрессионной модели возможно, но после оценивания параметров, модель подлежит дальнейшему многостороннему статистическому анализу.
- ?Если (0,49; 1], то будем считать, что у нас есть основания для использования регрессионной модели, при анализе поведения переменной у.
Пример 1. Вычислим коэффициент детерминации и сделаем предварительный вывод о качестве аппроксимации доходности акций компании Glenwood City Properties моделью линейной регрессии (пример 1).
Решение. Так как значение выборочного коэффициента корреляции нам уже известно, то для нахождения воспользуемся формулой (6):
И значение, и значение, говорят о слабой зависимости между доходностью рыночного индекса и доходностью акций указанной компании. Такая слабая зависимость обычно характерна для компаний с низкой рыночной капитализацией, которые не участвуют в формировании рыночного индекса. ^
Так, например, индекс S&P 500 (Standard & Poors Stock Price Index) представляет средневзвешенную величину курсов акций 500 наиболее крупных компаний. Наиболее часто цитируемым рыночным индексом является индекс Доу Джонса (DJIA), основанный на показателях всего 30 акций. Впервые этот индекс был вычислен в 1884 как среднеарифметическое 11 акций, с 1928 для расчета индекса используется 30 ценных бумаг. Состав бумаг, входящих в индекс, периодически меняется.
Коэффициент детерминации
Для оценки качества подбора линейной функции (близости расположения фактических данных к рассчитанной линии регрессии) рассчитывается квадрат линейного коэффициента корреляции , называемый коэффициентом детерминации.
Проверка осуществляется на основе исследования коэффициента детерминации и проведения дисперсионного анализа.
Регрессионная модель показывает, что вариация Y может быть объяснена вариацией независимой переменной Х и значением возмущения e. Мы хотим знать, насколько вариация Y обусловлена изменением Х и насколько она является следствием случайных причин. Другими словами, нам нужно знать, насколько хорошо рассчитанное уравнение регрессии соответствует фактическим данным, т.е. насколько мала вариация данных вокруг линии регрессии.
Для оценки степени соответствия линии регрессии нужно рассчитать коэффициент детерминации, суть которого можно хорошо уяснить, рассматривая разложение общей суммы квадратов отклонений переменной Y от среднего значения на две части – «объясненную» и «необъясненную» (рис. 4).
Из рис. 4 видно, что ![]() .
.
Возведем обе части этого равенства в квадрат и просуммируем по всем i от 1 до n .
Перепишем сумму произведений в виде:

Здесь использованы следующие свойства:
2) метод наименьших квадратов (МНК)исходит из условия:
необходимым условием существования минимума функции Q является равенство нулю ее первых частных производных по b 0 и b 1 .
![]() .
.
Или ![]() .
.
Отсюда следует, что .
 |
 |
 Y i
Y i

 |
|||||
Рисунок 4. Структура вариации зависимой переменной Y
Таким образом, в результате будем иметь:
 (1)
(1)
Общая сумма квадратов отклонений индивидуальных значений зависимой переменной Y от среднего значения вызвана влиянием множества причин, которые мы условно разделили на две группы: фактор Х и прочие факторы (случайные воздействия). Если фактор Х не оказывает влияния на результат (Y), то линия регрессии на графике параллельна оси абсцисс и . Тогда вся дисперсия зависимой переменной Y обусловлена воздействием прочих факторов, и общая сумма квадратов отклонений совпадает с остаточной суммой квадратов. Если же прочие факторы не влияют на результат, то Y связан с Х функционально, и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объясненная регрессией, совпадает с общей суммой квадратов.
Разделим обе части уравнения (1) на левую часть (на общую сумму квадратов), получим:
 (2)
(2)
Доля дисперсии зависимой переменной, объясненная регрессией, называется коэффициентом детерминации и обозначается R 2 . Из (2) коэффициент детерминации определяется:
 . (3)
. (3)
Величина коэффициента детерминации находится в пределах от 0 до 1 и служит одним из критериев проверки качества линейной модели. Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов, следовательно, линейная модель хорошо аппроксимирует исходные данные, и ею можно пользоваться для прогноза значений результативного признака.
коэффициент детерминации принимает значения от нуля, когда х не влияют на У, до единицы, когда изменение У полностью объясняется изменением х . Таким образом, коэффициент детерминации характеризует «полноту» модели.
Преимущества коэффициента детерминации: он легко вычисляется, интуитивно понятен и имеет четкую интерпретацию. Но несмотря на это его использование иногда связано с проблемами:
· нельзя сравнивать величины R 2 для моделей с различными зависимыми переменными;
· R 2 всегда возрастает по мере включения новых переменных в модель. Это свойство R 2 может создавать у исследователя стимул необоснованно включать дополнительные переменные в модель, и в любом случае становится проблематичным определить, улучшает ли дополнительная переменная качество модели;
· R 2 малопригоден для оценки качества моделей временных рядов, т.к. в таких моделях его значение часто достигает величины 0,9 и выше; дифференциация моделей на основании данного коэффициента является трудновыполнимой задачей.
Одна из перечисленных проблем – увеличение R 2 при введении в модель дополнительных переменных – решается путем коррекции коэффициента на уменьшение числа степеней свободы в результате появления в модели дополнительных переменных.
Скорректированный коэффициент детерминации рассчитывается так:
![]() , (4)
, (4)
Как видно из формулы, при добавлении переменных будет увеличиваться только в том случае, если рост R 2 будет «перевешивать» увеличение количества переменных. Действительно,
т.е. доля остаточной дисперсии с включением новых переменных должна уменьшаться, но, умноженная на она, в то же время, будет расти с ростом числа включенных в модель переменных (р); в итоге, если положительный эффект от включения новых факторов «перевесит» изменение числа степеней свободы, то увеличится; в противном случае – может и уменьшиться.
Оценка качества уравнения (адекватности выбранной модели эмпирическим данным) производится с помощью F-теста. Суть оценки сводится к проверке нулевой гипотезы Н 0 о статистической незначимости уравнения регрессии и коэффициента детерминации. Для этого выполняется сравнение фактического F факт и критического (табличного) F табл значений F-критерия Фишера:
![]() . (5)
. (5)
В случае справедливости гипотезы
Н 0: b 0 = b 1 = … = b р = 0 (или R 2 истин = 0)
статистика F факт должна подчиняться F – распределению с числом степеней свободы числителя и знаменателя, соответственно равными
n 1 = р и n 2 = n – p – 1.
Табличное значение F-критерия для вероятности 0,95 (или 0,99) и числа степеней свободы n 1 = р, n 2 = n – p – 1 сравнивается с вычисленным; при выполнении неравенства F > F табл отвергается нулевая гипотеза о том, что истинное значение коэффициента детерминации равно нулю; это дает основание считать, что модель адекватна исследуемому процессу.
Для парной модели в критерии проверки для R 2 числителю соответствует одна степень свободы и (n – 2) степеней свободы соответствует знаменателю. Расчет F-критерия для проверки значимости R 2 выполняется следующим образом:
 .
.
Обратившись к F-таблице, видим, что табличное значение при 5%-м уровне значимости для n 1 = 1 и n 2 = 50 составляет примерно 4. Так как расчетное значение F-критерия больше табличного, то при доверительной вероятности 0,95 отвергаем нулевую гипотезу о том, что истинное значение коэффициента детерминации равно нулю.
Таким образом, можно сделать вывод о том, что коэффициент детерминации (а значит, и модель в целом) являются статистически надежным показателем взаимосвязи рассматриваемых фондовых индексов.
Квадратный корень из величины коэффициента детерминации для парной модели является коэффициентом корреляции – показателем тесноты связи.
Третья стадия – проверка выполнимости основных предпосылок классической регрессии – предмет дальнейшего изучения .






