
А) Графический анализ простой линейной регрессии.
Простое линейное уравнение регрессии y=a+bx. Если между случайными величинами У и X существует корреляционная связь, то значение у = ý + ,
где ý – теоретическое значение у, полученное из уравнения ý = f(x),
– погрешность отклонения теоретического уравнения ý от фактических (экспериментальных) данных.
Уравнение зависимости средней величины ý от х, то есть ý = f(x) называют уравнением регрессии. Регрессионный анализ состоит из четырёх зтапов:
1) постановка задачи и установление причин связи.
2) ограничение объекта исследований, сбор статастической информации.
3) выбор уравнения связи на основе анализа и характера собранных данных.
4) расчёт числовых значений, характеристик корреляционной связи.
Если две переменные связаны таким образом, что изменение одной переменной соответствует систематическому изменению другой переменной, то для оценки и выбора уравнения связи между ними применяют регрессионный анализ в том случае, если эти переменные известны. В отличие от регрессионного анализа, корреляционный анализ применяют для анализа тесноты связи между X и У.
Рассмотрим нахождение прямой при регрессионном анализе:
Теоретическое уравнение регрессии.
Термин «простая регрессия» указывает на то, что величина одной переменной оценивается на основе знаний о другой переменной. В отличие от простой многофакторная регрессия применяется для оценки переменной на основе знания двух, трёх и более переменных. Рассмотрим графический анализ простой линейной регрессии.
Предположим, имеются результаты отборочных испытании по предварительному найму на работу и производительности труда.
|
Результаты отбора (100 баллов), x |
Производительность (20 баллов), y |
|
Нанеся точки на график, получим диаграмму (поле) рассеяния. Используем её для анализа результатов отборочных испытаний и производительности труда.
По диаграмме рассеяния проанализируем линию регрессии. В регрессионном анализе всегда указываются хотя бы две переменные. Систематическое изменение одной переменной связано с изменением другой. Основная цель регрессионного анализа заключается в оценке величины одной переменной, если величина другой переменной известна. Для полной задачи важна оценка производительности труда.
Независимой переменной в регрессионном анализе называется величина, которая используется в качестве основы для анализа другой переменной. В данном случае – это результаты отборочных испытаний (по оси X).
Зависимой переменной называется оцениваемая величина (по оси У). В регрессионном анализе может быть только одна зависимая переменная и несколько независимых переменных.
Для простого регрессионного анализа зависимость можно представить в двухкоординатной системе (х и у), по оси X – независимая переменная, по оси У – зависимая. Наносим точки пересечения таким образом, чтобы на графике была представлена пара величин. График называют диаграммой рассеяния . Ее построение – это второй этап регрессионного анализа, поскольку первый – это выбор анализируемых величин и сбор данных выборки. Таким образом, регрессионный анализ применяется для статистического анализа. Связь между выборочными данными диаграммы линейная.
Для оценки величины переменной у на основе переменной х необходимо определить положение линии, которая наилучшим образом представляет связь между х и у на основе расположения точек диаграммы рассеяния. В нашем примере это анализ производительности. Линия, проведенная через точки рассеяния – линия регрессии . Одним из способов построения линии регрессии, основанном на визуальном опыте, является способ построения от руки. По нашей линии регрессии можно определить производительность труда. При нахождении уравнения линии регрессии


часто применяют критерий наименьших квадратов. Наиболее подходящей является та линия, где сумма квадратов отклонений минимальна

Математическое уравнение линии роста представляет закон роста в арифметической прогрессии:
у = а – b х .
Y = а + b х – приведённое уравнение с одним параметром является простейшим видом уравнения связи. Оно приемлемо для средних величин. Чтобы точнее выразить связь между х и у , вводится дополнительный коэффициент пропорциональности b , который указывает наклон линии регрессии.
Б) Построение теоретической линии регрессии.
Процесс её нахождения заключается в выборе и обосновании типа кривой и расчётов параметров а , b , с и т.д. Процесс построения называют выравниванием, и запас кривых, предлагаемых мат. анализом, разнообразен. Чаще всего в экономических задачах используют семейство кривых, уравнения которые выражаются многочленами целых положительных степеней.
1)
 – уравнение прямой,
– уравнение прямой,
2)
 – уравнение гиперболы,
– уравнение гиперболы,
3)
 – уравнение параболы,
– уравнение параболы,
где ý – ординаты теоретической линии регрессии.
Выбрав тип уравнения, необходимо найти параметры, от которых зависит это уравнение. Например, характер расположения точек в поле рассеяния показал, что теоретическая линия регрессии является прямой.
Диаграмма рассеяния позволяет представить производительность труда с помощью регрессионного анализа. В экономике с помощью регрессионного анализа предсказываются многие характеристики, влияющие на конечный продукт (с учётом ценообразования).
В) Критерий наименьших кадратов для нахождения прямой линии.
Один из критериев, которые мы могли бы применить для подходящей линии регрессии на диаграмме рассеяния, основан на выборе линии, для которой сумма квадратов погрешностей будет минимальна.

Близость точек рассеяния к прямой измеряется ординатами отрезков. Отклонения этих точек могут быть положительными и отрицательными, но сумма квадратов отклонений теоретической прямой от экспериментальной всегда положительна и должна быть минимальна. Факт несовпадения всех точек рассеяния с положением линии регрессии указывает на существование расхождения между экспериментальными и теоретическими данными. Таким образом, можно сказать, что никакая другая линия регрессии, кроме той, которую нашли, не может дать меньшую сумму отклонений между экспериментальными и опытными данными. Следовательно, найдя теоретическое уравнение ý и линию регрессии, мы удовлетворяем требованию наименьших квадратов.
Это делается с
помощью уравнения связи
 ,
используя формулы для нахождения
параметров а
и b
.
Взяв теоретическое значение
,
используя формулы для нахождения
параметров а
и b
.
Взяв теоретическое значение
 и обозначив левую часть уравнения черезf
,
получим функцию
и обозначив левую часть уравнения черезf
,
получим функцию
 от неизвестных параметрова
и b
.
Значения а
и b
будут удовлетворять минимуму функции
f
и находятся из уравнений частных
производных
от неизвестных параметрова
и b
.
Значения а
и b
будут удовлетворять минимуму функции
f
и находятся из уравнений частных
производных
 и
и .
Этонеобходимое
условие
,
однако для положительной квадратической
функции это является и достаточным
условием для нахождения а
и b
.
.
Этонеобходимое
условие
,
однако для положительной квадратической
функции это является и достаточным
условием для нахождения а
и b
.
Выведем из уравнений частных производных формулы параметров а и b :




получим систему уравнений:

 где
где
 – среднеарифметические погрешности.
– среднеарифметические погрешности.
Подставив числовые значения, найдем параметры а и b .
Существует понятие
 .
Это коэффициент аппроксимации.
.
Это коэффициент аппроксимации.
Если е < 33%, то модель приемлема для дальнейшего анализа;
Если е > 33%, то берём гиперболу, параболу и т.д. Это даёт право для анализа в различных ситуациях.
Вывод: по критерию коэффициента аппроксимации наиболее подходящей является та линия, для которых
 ,
и никакая другая линия регрессии для
нашей задачи не даёт минимум отклонений.
,
и никакая другая линия регрессии для
нашей задачи не даёт минимум отклонений.
Г) Квадратическая ошибка оценки, проверка их типичности.
Применительно к совокупности, у которой число параметров исследования меньше 30 (n < 30), для проверки типичности параметров уравнения регрессии используется t -критерий Стьюдента. При этом вычисляется фактическое значение t -критерия:


Отсюда


где
 – остаточная среднеквадратическая
погрешность. Полученныеt
a
и
t
b
сравнивают с критическим t
k
из таблицы Стьюдента с учётом принятого
уровня значимости (
= 0,01 = 99% или
= 0,05 = 95%). P
= f
= k
1
= m
– число параметров исследуемого
уравнения (степень свободы). Например,
если y
= a
+ bx
;
m
= 2, k
2
= f
2
= p
2
= n
– (m
+ 1), где n
– количество исследуемых признаков.
– остаточная среднеквадратическая
погрешность. Полученныеt
a
и
t
b
сравнивают с критическим t
k
из таблицы Стьюдента с учётом принятого
уровня значимости (
= 0,01 = 99% или
= 0,05 = 95%). P
= f
= k
1
= m
– число параметров исследуемого
уравнения (степень свободы). Например,
если y
= a
+ bx
;
m
= 2, k
2
= f
2
= p
2
= n
– (m
+ 1), где n
– количество исследуемых признаков.
t a < t k < t b .
Вывод
:
по проверенным
на типичность параметрам уравнения
регрессии производится построение
математической модели связи
 .
При этом параметры примененной в анализе
математической функции (линейная,
гипербола, парабола) получают
соответствующие количественные значения.
Смысловое содержание полученных таким
образом моделей состоит в том, что они
характеризуют среднюю величину
результативного признака
.
При этом параметры примененной в анализе
математической функции (линейная,
гипербола, парабола) получают
соответствующие количественные значения.
Смысловое содержание полученных таким
образом моделей состоит в том, что они
характеризуют среднюю величину
результативного признака от факторного
признака X
.
от факторного
признака X
.
Д) Криволинейная регрессия.
Довольно часто встречается криволинейная зависимость, когда между переменными устанавливается меняющееся соотношение. Интенсивность возрастания (убывания) зависит от уровня нахождения X. Криволинейная зависимость бывает разных видов. Например, рассмотрим зависимость между урожаем и осадками. С увеличением осадков при равных природных условиях интенсивное увеличение урожая, но до определенного предела. После критической точки осадки оказываются излишними, и урожайность катастрофически падает. Из примера видно, что вначале связь была положительной, а потом отрицательной. Критическая точка - оптимальный уровень признака X, которому соответствует максимальное или минимальное значение признака У.
В экономике такая связь наблюдается между ценой и потреблением, производительностью и стажем.
Параболическая зависимость.
Если данные показывают, что увеличение факторного признака приводит к росту результативного признака, то в качестве уравнения регрессии берется уравнение второго порядка (парабола).
 .
Коэффициенты a,b,c
находятся из уравнений частных
производных:
.
Коэффициенты a,b,c
находятся из уравнений частных
производных:

Получаем систему уравнений:

Виды криволинейных уравнений:
 ,
,
 ,
,


Вправе предполагать, что между производительностью труда и баллами отборочных испытаний существует криволинейная зависимость. Это означает, что с ростом бальной системы производительность начнёт на каком-то уровне уменьшаться, поэтому прямая модель может оказаться криволинейной.
Третьей моделью будет гипербола, и во всех уравнениях вместо переменной х будет стоять выражение .
Основная особенность регрессионного анализа: при его помощи можно получить конкретные сведения о том, какую форму и характер имеет зависимость между исследуемыми переменными.
Последовательность этапов регрессионного анализа
Рассмотрим кратко этапы регрессионного анализа.
Формулировка задачи. На этом этапе формируются предварительные гипотезы о зависимости исследуемых явлений.
Определение зависимых и независимых (объясняющих) переменных.
Сбор статистических данных. Данные должны быть собраны для каждой из переменных, включенных в регрессионную модель.
Формулировка гипотезы о форме связи (простая или множественная, линейная или нелинейная).
Определение функции регрессии (заключается в расчете численных значений параметров уравнения регрессии)
Оценка точности регрессионного анализа.
Интерпретация полученных результатов. Полученные результаты регрессионного анализа сравниваются с предварительными гипотезами. Оценивается корректность и правдоподобие полученных результатов.
Предсказание неизвестных значений зависимой переменной.
При помощи регрессионного анализа возможно решение задачи прогнозирования и классификации. Прогнозные значения вычисляются путем подстановки в уравнение регрессии параметров значений объясняющих переменных. Решение задачи классификации осуществляется таким образом: линия регрессии делит все множество объектов на два класса, и та часть множества, где значение функции больше нуля, принадлежит к одному классу, а та, где оно меньше нуля, - к другому классу.
Задачи регрессионного анализа
Рассмотрим основные задачи регрессионного анализа: установление формы зависимости, определение функции регрессии , оценка неизвестных значений зависимой переменной.
Установление формы зависимости.
Характер и форма зависимости между переменными могут образовывать следующие разновидности регрессии:
положительная линейная регрессия (выражается в равномерном росте функции);
положительная равноускоренно возрастающая регрессия;
положительная равнозамедленно возрастающая регрессия;
отрицательная линейная регрессия (выражается в равномерном падении функции);
отрицательная равноускоренно убывающая регрессия;
отрицательная равнозамедленно убывающая регрессия.
Однако описанные разновидности обычно встречаются не в чистом виде, а в сочетании друг с другом. В таком случае говорят о комбинированных формах регрессии.
Определение функции регрессии.
Вторая задача сводится к выяснению действия на зависимую переменную главных факторов или причин, при неизменных прочих равных условиях, и при условии исключения воздействия на зависимую переменную случайных элементов. Функция регрессии определяется в виде математического уравнения того или иного типа.
Оценка неизвестных значений зависимой переменной.
Решение этой задачи сводится к решению задачи одного из типов:
Оценка значений зависимой переменной внутри рассматриваемого интервала исходных данных, т.е. пропущенных значений; при этом решается задача интерполяции.
Оценка будущих значений зависимой переменной, т.е. нахождение значений вне заданного интервала исходных данных; при этом решается задача экстраполяции.
Обе задачи решаются путем подстановки в уравнение регрессии найденных оценок параметров значений независимых переменных. Результат решения уравнения представляет собой оценку значения целевой (зависимой) переменной.
Рассмотрим некоторые предположения, на которые опирается регрессионный анализ.
Предположение линейности, т.е. предполагается, что связь между рассматриваемыми переменными является линейной. Так, в рассматриваемом примере мы построили диаграмму рассеивания и смогли увидеть явную линейную связь. Если же на диаграмме рассеивания переменных мы видим явное отсутствие линейной связи, т.е. присутствует нелинейная связь, следует использовать нелинейные методы анализа.
Предположение о нормальности остатков . Оно допускает, что распределение разницы предсказанных и наблюдаемых значений является нормальным. Для визуального определения характера распределения можно воспользоваться гистограммамиостатков .
При использовании регрессионного анализа следует учитывать его основное ограничение. Оно состоит в том, что регрессионный анализ позволяет обнаружить лишь зависимости, а не связи, лежащие в основе этих зависимостей.
Регрессионный анализ дает возможность оценить степень связи между переменными путем вычисления предполагаемого значения переменной на основании нескольких известных значений.
Уравнение регрессии.
Уравнение регрессии выглядит следующим образом: Y=a+b*X
При помощи этого уравнения переменная Y выражается через константу a и угол наклона прямой (или угловой коэффициент) b, умноженный на значение переменной X. Константу a также называют свободным членом, а угловой коэффициент - коэффициентом регрессии или B-коэффициентом.
В большинстве случав (если не всегда) наблюдается определенный разброс наблюдений относительно регрессионной прямой.
Остаток - это отклонение отдельной точки (наблюдения) от линии регрессии (предсказанного значения).
Для решения задачи регрессионного анализа в MS Excel выбираем в меню Сервис "Пакет анализа" и инструмент анализа "Регрессия". Задаем входные интервалы X и Y. Входной интервал Y - это диапазон зависимых анализируемых данных, он должен включать один столбец. Входной интервал X - это диапазон независимых данных, которые необходимо проанализировать. Число входных диапазонов должно быть не больше 16.
На выходе процедуры в выходном диапазоне получаем отчет, приведенный в таблице 8.3а -8.3в .
ВЫВОД ИТОГОВ
|
Таблица 8.3а. Регрессионная статистика |
|
|
Регрессионная статистика |
|
|
Множественный R | |
|
R-квадрат | |
|
Нормированный R-квадрат | |
|
Стандартная ошибка | |
|
Наблюдения | |
Сначала рассмотрим верхнюю часть расчетов, представленную в таблице 8.3а , - регрессионную статистику.
Величина R-квадрат , называемая также мерой определенности, характеризует качество полученной регрессионной прямой. Это качество выражается степенью соответствия между исходными данными и регрессионной моделью (расчетными данными). Мера определенности всегда находится в пределах интервала .
В большинстве случаев значение R-квадрат находится между этими значениями, называемыми экстремальными, т.е. между нулем и единицей.
Если значение R-квадрата близко к единице, это означает, что построенная модель объясняет почти всю изменчивость соответствующих переменных. И наоборот, значениеR-квадрата , близкое к нулю, означает плохое качество построенной модели.
В нашем примере мера определенности равна 0,99673, что говорит об очень хорошей подгонке регрессионной прямой к исходным данным.
множественный R - коэффициент множественной корреляции R - выражает степень зависимости независимых переменных (X) и зависимой переменной (Y).
Множественный R равен квадратному корню из коэффициента детерминации, эта величина принимает значения в интервале от нуля до единицы.
В простом линейном регрессионном анализе множественный R равен коэффициенту корреляции Пирсона. Действительно,множественный R в нашем случае равен коэффициенту корреляции Пирсона из предыдущего примера (0,998364).
|
Таблица 8.3б. Коэффициенты регрессии |
|||
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
|
|
Y-пересечение | |||
|
Переменная X 1 | |||
|
* Приведен усеченный вариант расчетов |
|||
Теперь рассмотрим среднюю часть расчетов, представленную в таблице 8.3б . Здесь даны коэффициент регрессии b (2,305454545) и смещение по оси ординат, т.е. константа a (2,694545455).
Исходя из расчетов, можем записать уравнение регрессии таким образом:
Y= x*2,305454545+2,694545455
Направление связи между переменными определяется на основании знаков (отрицательный или положительный) коэффициентов регрессии (коэффициента b).
Если знак при коэффициенте регрессии - положительный, связь зависимой переменной с независимой будет положительной. В нашем случае знак коэффициента регрессии положительный, следовательно, связь также является положительной.
Если знак при коэффициенте регрессии - отрицательный, связь зависимой переменной с независимой является отрицательной (обратной).
В таблице 8.3в . представлены результаты выводаостатков . Для того чтобы эти результаты появились в отчете, необходимо при запуске инструмента "Регрессия" активировать чекбокс "Остатки".
ВЫВОД ОСТАТКА
|
Таблица 8.3в. Остатки |
|||
|
Наблюдение |
Предсказанное Y |
Остатки |
Стандартные остатки |
При помощи этой части отчета мы можем видеть отклонения каждой точки от построенной линии регрессии. Наибольшее абсолютное значение остатка в нашем случае - 0,778, наименьшее - 0,043. Для лучшей интерпретации этих данных воспользуемся графиком исходных данных и построенной линией регрессии, представленными нарис. 8.3 . Как видим, линия регрессии достаточно точно "подогнана" под значения исходных данных.
Следует учитывать, что рассматриваемый пример является достаточно простым и далеко не всегда возможно качественное построение регрессионной прямой линейного вида.
Рис. 8.3. Исходные данные и линия регрессии
Осталась нерассмотренной задача оценки неизвестных будущих значений зависимой переменной на основании известных значений независимой переменной, т.е. задача прогнозирования.
Имея уравнение регрессии, задача прогнозирования сводится к решению уравнения Y= x*2,305454545+2,694545455 с известными значениями x. Результаты прогнозирования зависимой переменной Y на шесть шагов вперед представлены в таблице 8.4 .
|
Таблица 8.4. Результаты прогнозирования переменной Y |
|
|
Y(прогнозируемое) |
|
Таким образом, в результате использования регрессионного анализа в пакете Microsoft Excel мы:
построили уравнение регрессии;
установили форму зависимости и направление связи между переменными - положительная линейная регрессия, которая выражается в равномерном росте функции;
установили направление связи между переменными;
оценили качество полученной регрессионной прямой;
смогли увидеть отклонения расчетных данных от данных исходного набора;
предсказали будущие значения зависимой переменной.
Если функция регрессии определена, интерпретирована и обоснована, и оценка точности регрессионного анализа соответствует требованиям, можно считать, что построенная модель и прогнозные значения обладают достаточной надежностью.
Прогнозные значения, полученные таким способом, являются средними значениями, которые можно ожидать.
В этой работе мы рассмотрели основные характеристики описательной статистики и среди них такие понятия, каксреднее значение ,медиана ,максимум ,минимум и другие характеристики вариации данных.
Также было кратко рассмотрено понятие выбросов . Рассмотренные характеристики относятся к так называемому исследовательскому анализу данных, его выводы могут относиться не к генеральной совокупности, а лишь к выборке данных. Исследовательский анализ данных используется для получения первичных выводов и формирования гипотез относительно генеральной совокупности.
Также были рассмотрены основы корреляционного и регрессионного анализа, их задачи и возможности практического использования.
Регрессионный анализ -- метод моделирования измеряемых данных и исследования их свойств. Данные состоят из пар значений зависимой переменной (переменной отклика) и независимой переменной (объясняющей переменной). Регрессионная модель есть функция независимой переменной и параметров с добавленной случайной переменной.
Корреляционный анализ и регрессионный анализ являются смежными разделами математической статистики, и предназначаются для изучения по выборочным данным статистической зависимости ряда величин; некоторые из которых являются случайными. При статистической зависимости величины не связаны функционально, но как случайные величины заданы совместным распределением вероятностей.
Исследование зависимости случайных величин приводит к моделям регрессии и регрессионному анализу на базе выборочных данных. Теория вероятностей и математическая статистика представляют лишь инструмент для изучения статистической зависимости, но не ставят своей целью установление причинной связи. Представления и гипотезы о причинной связи должны быть привнесены из некоторой другой теории, которая позволяет содержательно объяснить изучаемое явление.
Числовые данные обычно имеют между собой явные (известные) или неявные (скрытые) связи.
Явно связаны показатели, которые получены методами прямого счета, т. е. вычислены по заранее известным формулам. Например, проценты выполнения плана, уровни, удельные веса, отклонения в сумме, отклонения в процентах, темпы роста, темпы прироста, индексы и т. д.
Связи же второго типа (неявные) заранее неизвестны. Однако необходимо уметь объяснять и предсказывать (прогнозировать) сложные явления для того, чтобы управлять ими. Поэтому специалисты с помощью наблюдений стремятся выявить скрытые зависимости и выразить их в виде формул, т. е. математически смоделировать явления или процессы. Одну из таких возможностей предоставляет корреляционно-регрессионный анализ.
Математические модели строятся и используются для трех обобщенных целей:
- * для объяснения;
- * для предсказания;
- * для управления.
Пользуясь методами корреляционно-регрессионного анализа, аналитики измеряют тесноту связей показателей с помощью коэффициента корреляции. При этом обнаруживаются связи, различные по силе (сильные, слабые, умеренные и др.) и различные по направлению (прямые, обратные). Если связи окажутся существенными, то целесообразно будет найти их математическое выражение в виде регрессионной модели и оценить статистическую значимость модели.
Регрессионный анализ называют основным методом современной математической статистики для выявления неявных и завуалированных связей между данными наблюдений.
Постановка задачи регрессионного анализа формулируется следующим образом.
Имеется совокупность результатов наблюдений. В этой совокупности один столбец соответствует показателю, для которого необходимо установить функциональную зависимость с параметрами объекта и среды, представленными остальными столбцами. Требуется: установить количественную взаимосвязь между показателем и факторами. В таком случае задача регрессионного анализа понимается как задача выявления такой функциональной зависимости y = f (x2, x3, …, xт), которая наилучшим образом описывает имеющиеся экспериментальные данные.
Допущения:
количество наблюдений достаточно для проявления статистических закономерностей относительно факторов и их взаимосвязей;
обрабатываемые данные содержат некоторые ошибки (помехи), обусловленные погрешностями измерений, воздействием неучтенных случайных факторов;
матрица результатов наблюдений является единственной информацией об изучаемом объекте, имеющейся в распоряжении перед началом исследования.
Функция f (x2, x3, …, xт), описывающая зависимость показателя от параметров, называется уравнением (функцией) регрессии. Термин "регрессия" (regression (лат.) - отступление, возврат к чему-либо) связан со спецификой одной из конкретных задач, решенных на стадии становления метода.
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
предварительная обработка данных;
выбор вида уравнений регрессии;
вычисление коэффициентов уравнения регрессии;
проверка адекватности построенной функции результатам наблюдений.
Предварительная обработка включает стандартизацию матрицы данных, расчет коэффициентов корреляции, проверку их значимости и исключение из рассмотрения незначимых параметров.
Выбор вида уравнения регрессии Задача определения функциональной зависимости, наилучшим образом описывающей данные, связана с преодолением ряда принципиальных трудностей. В общем случае для стандартизованных данных функциональную зависимость показателя от параметров можно представить в виде
y = f (x1, x2, …, xm) + e
где f - заранее не известная функция, подлежащая определению;
e - ошибка аппроксимации данных.
Указанное уравнение принято называть выборочным уравнением регрессии. Это уравнение характеризует зависимость между вариацией показателя и вариациями факторов. А мера корреляции измеряет долю вариации показателя, которая связана с вариацией факторов. Иначе говоря, корреляцию показателя и факторов нельзя трактовать как связь их уровней, а регрессионный анализ не объясняет роли факторов в создании показателя.
Еще одна особенность касается оценки степени влияния каждого фактора на показатель. Регрессионное уравнение не обеспечивает оценку раздельного влияния каждого фактора на показатель, такая оценка возможна лишь в случае, когда все другие факторы не связаны с изучаемым. Если изучаемый фактор связан с другими, влияющими на показатель, то будет получена смешанная характеристика влияния фактора. Эта характеристика содержит как непосредственное влияние фактора, так и опосредованное влияние, оказанное через связь с другими факторами и их влиянием на показатель.
В регрессионное уравнение не рекомендуется включать факторы, слабо связанные с показателем, но тесно связанные с другими факторами. Не включают в уравнение и факторы, функционально связанные друг с другом (для них коэффициент корреляции равен 1). Включение таких факторов приводит к вырождению системы уравнений для оценок коэффициентов регрессии и к неопределенности решения.
Функция f должна подбираться так, чтобы ошибка e в некотором смысле была минимальна. В целях выбора функциональной связи заранее выдвигают гипотезу о том, к какому классу может принадлежать функция f, а затем подбирают "лучшую" функцию в этом классе. Выбранный класс функций должен обладать некоторой "гладкостью", т.е. "небольшие" изменения значений аргументов должны вызывать "небольшие" изменения значений функции.
Частным случаем, широко применяемым на практике, является полином первой степени или уравнение линейной регрессии
Для выбора вида функциональной зависимости можно рекомендовать следующий подход:
в пространстве параметров графически отображают точки со значениями показателя. При большом количестве параметров можно строить точки применительно к каждому из них, получая двумерные распределения значений;
по расположению точек и на основе анализа сущности взаимосвязи показателя и параметров объекта делают заключение о примерном виде регрессии или ее возможных вариантах;
после расчета параметров оценивают качество аппроксимации, т.е. оценивают степень близости расчетных и фактических значений;
если расчетные и фактические значения близки во всей области задания, то задачу регрессионного анализа можно считать решенной. В противном случае можно попытаться выбрать другой вид полинома или другую аналитическую функцию, например периодическую.
Вычисление коэффициентов уравнения регрессии
Систему уравнений на основе имеющихся данных однозначно решить невозможно, так как количество неизвестных всегда больше количества уравнений. Для преодоления этой проблемы нужны дополнительные допущения. Здравый смысл подсказывает: желательно выбрать коэффициенты полинома так, чтобы обеспечить минимум ошибки аппроксимации данных. Могут применяться различные меры для оценки ошибок аппроксимации. В качестве такой меры нашла широкое применение среднеквадратическая ошибка. На ее основе разработан специальный метод оценки коэффициентов уравнений регрессии - метод наименьших квадратов (МНК). Этот метод позволяет получить оценки максимального правдоподобия неизвестных коэффициентов уравнения регрессии при нормальном распределения вариант, но его можно применять и при любом другом распределении факторов.
В основе МНК лежат следующие положения:
значения величин ошибок и факторов независимы, а значит, и некоррелированы, т.е. предполагается, что механизмы порождения помехи не связаны с механизмом формирования значений факторов;
математическое ожидание ошибки e должно быть равно нулю (постоянная составляющая входит в коэффициент a0), иначе говоря, ошибка является центрированной величиной;
выборочная оценка дисперсии ошибки должна быть минимальна.
Если же линейная модель неточна или параметры измеряются неточно, то и в этом случае МНК позволяет найти такие значения коэффициентов, при которых линейная модель наилучшим образом описывает реальный объект в смысле выбранного критерия среднеквадратического отклонения.
Качество полученного уравнения регрессии оценивают по степени близости между результатами наблюдений за показателем и предсказанными по уравнению регрессии значениями в заданных точках пространства параметров. Если результаты близки, то задачу регрессионного анализа можно считать решенной. В противном случае следует изменить уравнение регрессии и повторить расчеты по оценке параметров.
При наличии нескольких показателей задача регрессионного анализа решается независимо для каждого из них.
Анализируя сущность уравнения регрессии, следует отметить следующие положения. Рассмотренный подход не обеспечивает раздельной (независимой) оценки коэффициентов - изменение значения одного коэффициента влечет изменение значений других. Полученные коэффициенты не следует рассматривать как вклад соответствующего параметра в значение показателя. Уравнение регрессии является всего лишь хорошим аналитическим описанием имеющихся данных, а не законом, описывающим взаимосвязи параметров и показателя. Это уравнение применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т.е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Главной причиной неточности прогноза является не столько неопределенность экстраполяции линии регрессии, сколько значительная вариация показателя за счет неучтенных в модели факторов. Ограничением возможности прогнозирования служит условие стабильности неучтенных в модели параметров и характера влияния учтенных факторов модели. Если резко меняется внешняя среда, то составленное уравнение регрессии потеряет свой смысл.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза. Для индивидуальных значений показателя интервал должен учитывать ошибки в положении линии регрессии и отклонения индивидуальных значений от этой линии .
Понятия корреляции и регрессии непосредственно связаны между собой. В корреляционном и регрессионном анализе много общих вычислительных приемов. Они используются для выявления причинно-следственных соотношений между явлениями и процессами. Однако, если корреляционный анализ позволяет оценить силу и направление стохастической связи, то регрессионный анализ - еще и форму зависимости.
Регрессия может быть:
а) в зависимости от числа явлений (переменных):
Простой (регрессия между двумя переменными);
Множественной (регрессия между зависимой переменной (y) и несколькими объясняющими ее переменными (х1, х2...хn);
б) в зависимости от формы:
Линейной (отображается линейной функцией, а между изучаемыми переменными существуют линейные соотношения);
Нелинейной (отображается нелинейной функцией, между изучаемыми переменными связь носит нелинейный характер);
в) по характеру связи между включенными в рассмотрение переменными:
Положительной (увеличение значения объясняющей переменной приводит к увеличению значения зависимой переменной и наоборот);
Отрицательной (с увеличением значения объясняющей переменной значение объясняемой переменной уменьшается);
г) по типу:
Непосредственной (в этом случае причина оказывает прямое воздействие на следствие, т.е. зависимая и объясняющая переменные связаны непосредственно друг с другом);
Косвенной (объясняющая переменная оказывает опосредованное действие через третью или ряд других переменных на зависимую переменную);
Ложной (нонсенс регрессия) - может возникнуть при поверхностном и формальном подходе к исследуемым процессам и явлениям. Примером бессмысленных является регрессия, устанавливающая связь между уменьшением количества потребляемого алкоголя в нашей стране и уменьшением продажи стирального порошка.
При проведении регрессионного анализа решаются следующие основные задачи:
1. Определение формы зависимости.
2. Определение функции регрессии. Для этого используют математическое уравнение того или иного типа, позволяющее, во-первых, установить общую тенденцию изменения зависимой переменной, а, во-вторых, вычислить влияние объясняющей переменной (или нескольких переменных) на зависимую переменную.
3. Оценка неизвестных значений зависимой переменной. Полученная математическая зависимость (уравнение регрессии) позволяет определять значение зависимой переменной как в пределах интервала заданных значений объясняющих переменных, так и за его пределами. В последнем случае регрессионный анализ выступает в качестве полезного инструмента при прогнозировании изменений социально-экономических процессов и явлений (при условии сохранения существующих тенденций и взаимосвязей). Обычно длина временного отрезка, на который осуществляется прогнозирование, выбирается не более половины интервала времени, на котором проведены наблюдения исходных показателей. Можно осуществить как пассивный прогноз, решая задачу экстраполяции, так и активный, ведя рассуждения по известной схеме "если..., то" и подставляя различные значения в одну или несколько объясняющих переменных регрессии.
Для построения регрессии используется специальный метод, получивший название метода наименьших квадратов . Этот метод имеет преимущества перед другими методами сглаживания: сравнительно простое математическое определение искомых параметров и хорошее теоретическое обоснование с вероятностной точки зрения.
При выборе модели регрессии одним из существенных требований к ней является обеспечение наибольшей возможной простоты, позволяющей получить решение с достаточной точностью. Поэтому для установления статистических связей вначале, как правило, рассматривают модель из класса линейных функций (как наиболее простейшего из всех возможных классов функций):
где bi, b2...bj - коэффициенты, определяющие влияние независимых переменных хij на величину yi; аi - свободный член; ei - случайное отклонение, которое отражает влияние неучтенных факторов на зависимую переменную; n - число независимых переменных; N число наблюдений, причем должно соблюдаться условие (N . n+1).
Линейная модель может описывать весьма широкий класс различных задач. Однако на практике, в частности в социально-экономических системах, подчас затруднительно применение линейных моделей из-за больших ошибок аппроксимации. Поэтому нередко используются функции нелинейной множественной регрессии, допускающие линеаризацию. К их числу, например, относится производственная функция (степенная функция Кобба-Дугласа), нашедшая применение в различных социально-экономических исследованиях. Она имеет вид:
где b 0 - нормировочный множитель, b 1 ...b j - неизвестные коэффициенты, e i - случайное отклонение.
Используя натуральные логарифмы, можно преобразовать это уравнение в линейную форму:
Полученная модель позволяет использовать стандартные процедуры линейной регрессии, описанные выше. Построив модели двух видов (аддитивные и мультипликативные), можно выбрать наилучшие и провести дальнейшие исследования с меньшими ошибками аппроксимации.
Существует хорошо развитая система подбора аппроксимирующих функций - методика группового учета аргументов (МГУА) .
О правильности подобранной модели можно судить по результатам исследования остатков, являющихся разностями между наблюдаемыми величинами y i и соответствующими прогнозируемыми с помощью регрессионного уравнения величинами y i . В этом случае для проверки адекватности модели рассчитывается средняя ошибка аппроксимации:

Модель считается адекватной, если e находится в пределах не более 15%.
Особо подчеркнем, что применительно к социально-экономическим системам далеко не всегда выполняются основные условия адекватности классической регрессионной модели.
Не останавливаясь на всех причинах возникающей неадекватности, назовем лишь мультиколлинеарность - самую сложную проблему эффективного применения процедур регрессионного анализа при изучении статистических зависимостей. Под мультиколлинеарностью понимается наличие линейной связи между объясняющими переменными.
Это явление:
а) искажает смысл коэффициентов регрессии при их содержательной интерпретации;
б) снижает точность оценивания (возрастает дисперсия оценок);
в) усиливает чувствительность оценок коэффициентов к выборочным данным (увеличение объема выборки может сильно повлиять на значения оценок).
Существуют различные приемы снижения мультиколлинеарности. Наиболее доступный способ - устранение одной из двух переменных, если коэффициент корреляции между ними превышает значение, равное по абсолютной величине 0,8. Какую из переменных оставить решают, исходя из содержательных соображений. Затем вновь проводится расчет коэффициентов регрессии.
Использование алгоритма пошаговой регрессии позволяет последовательно включать в модель по одной независимой переменной и анализировать значимость коэффициентов регрессии и мультиколлинеарность переменных. Окончательно в исследуемой зависимости остаются только те переменные, которые обеспечивают необходимую значимость коэффициентов регрессии и минимальное влияние мультиколлинеарности.
Регрессионный анализ - это метод установления аналитического выражения стохастической зависимости между исследуемыми признаками. Уравнение регрессии показывает, как в среднем изменяется у при изменении любого из x i , и имеет вид:
где у - зависимая переменная (она всегда одна);
х i - независимые переменные (факторы) (их может быть несколько).
Если
независимая переменная одна - это простой
регрессионный анализ. Если же их несколько
(п
 2),
то такой
анализ называется многофакторным.
2),
то такой
анализ называется многофакторным.
В ходе регрессионного анализа решаются две основные задачи:
построение уравнения регрессии, т.е. нахождение вида зависимости между результатным показателем и независимыми факторами x 1 , x 2 , …, x n .
оценка значимости полученного уравнения, т.е. определение того, насколько выбранные факторные признаки объясняют вариацию признака у.
Применяется регрессионный анализ главным образом для планирования, а также для разработки нормативной базы.
В отличие от корреляционного анализа, который только отвечает на вопрос, существует ли связь между анализируемыми признаками, регрессионный анализ дает и ее формализованное выражение. Кроме того, если корреляционный анализ изучает любую взаимосвязь факторов, то регрессионный - одностороннюю зависимость, т.е. связь, показывающую, каким образом изменение факторных признаков влияет на признак результативный.
Регрессионный анализ - один из наиболее разработанных методов математической статистики. Строго говоря, для реализации регрессионного анализа необходимо выполнение ряда специальных требований (в частности, x l ,x 2 ,...,x n ; y должны быть независимыми, нормально распределенными случайными величинами с постоянными дисперсиями). В реальной жизни строгое соответствие требованиям регрессионного и корреляционного анализа встречается очень редко, однако оба эти метода весьма распространены в экономических исследованиях. Зависимости в экономике могут быть не только прямыми, но и обратными и нелинейными. Регрессионная модель может быть построена при наличии любой зависимости, однако в многофакторном анализе используют только линейные модели вида:
![]()
Построение уравнения регрессии осуществляется, как правило, методом наименьших квадратов, суть которого состоит в минимизации суммы квадратов отклонений фактических значений результатного признака от его расчетных значений, т.е.:

где т - число наблюдений;
 j
=
a + b
1 x
1 j
+
b
2 x
2 j
+
... + b
n
х
n
j
-
расчетное
значение результатного фактора.
j
=
a + b
1 x
1 j
+
b
2 x
2 j
+
... + b
n
х
n
j
-
расчетное
значение результатного фактора.
Коэффициенты регрессии рекомендуется определять с помощью аналитических пакетов для персонального компьютера или специального финансового калькулятора. В наиболее простом случае коэффициенты регрессии однофакторного линейного уравнения регрессии вида y = а + bх можно найти по формулам:

Кластерный анализ
Кластерный анализ - один из методов многомерного анализа, предназначенный для группировки (кластеризации) совокупности, элементы которой характеризуются многими признаками. Значения каждого из признаков служат координатами каждой единицы изучаемой совокупности в многомерном пространстве признаков. Каждое наблюдение, характеризующееся значениями нескольких показателей, можно представить как точку в пространстве этих показателей, значения которых рассматриваются как координаты в многомерном пространстве. Расстояние между точками р и q с k координатами определяется как:

Основным критерием кластеризации является то, что различия между кластерами должны быть более существенны, чем между наблюдениями, отнесенными к одному кластеру, т.е. в многомерном пространстве должно соблюдаться неравенство:
![]()
где r 1, 2 - расстояние между кластерами 1 и 2.
Так же как и процедуры регрессионного анализа, процедура кластеризации достаточно трудоемка, ее целесообразно выполнять на компьютере.
Открытие бизнеса

Где можно и где нельзя работать после туберкулеза Где можно работать после
Форекс
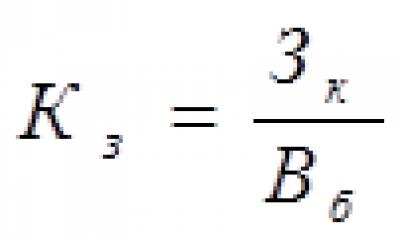
Направления повышения эффективности использования собственного капитала На базе двигателя с плоским печатным якорем разработаны изделия для автомобильной промышленности
Банки




