Таблица 1
Таблица 2
| № | Вид квадратичной формы | Вид ограничений |
| 1. | ||
| 2. | ||
| 3. | ||
| 4. | ||
| 5. | ||
| 6. | ||
| 7. | ||
| 8. | ||
| 9. | ||
| 10. | 2 |
Таблица 3
| Координаты начальной точки | |||||||||||||
| № | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 3 | 0 | -2 | 5 | 6 | 7,5 | 3 | 3 | 1 | 4 | 7 | 4 | 7 | |
| -2 | 1 | 12 | -3 | -2 | -2 | 0 | 4 | 2 | 3 | 1 | 4 | 3 | |
Этапы проектирования
- Постановка задачи в соответствии с вариантом задания.
- Представление заданной квадратичной формы в матричной форме записи.
- Исследование характера экстремума.
- Описание в матричной форме метода поиска и составление алгоритма.
- Составление структурной схемы алгоритма поиска.
- Программирование в среде Math Cad.
- Расчет.
- Выводы по работе.
Постановка и решение задач многомерной безусловной оптимизации
Задачи многомерной безусловной минимизации
Для заданной функции решить задачу многомерной безусловной минимизации f(x 1 , x 2), xX (XR) и начальной точки x 0 .Пусть f(x) = f(x 1 , x 2 , … ,x n) – действительная функция n переменных, определенная на множестве X Ì R n . Точка x* Î X называется точкой локального минимума f(x) на множестве X, если существует такая
e-окрестность этой точки, что для всех x из этой окрестности, т. е., если
|| x - x*|| < e, выполняется условие f(x*) £ f(x).
Если выполняется условие f(x*) < f(x), то x* называется точкой строгого локального минимума. У функции может быть несколько локальных минимумов. Точка x*Î X называется точкой глобального минимума f(x) на множестве X, если для всех x Î X выполняется условие f(x*) £ f(x). Значение функции f(x*) называется минимальным значением f(x) на множестве X. Для нахождения глобального минимума необходимо найти все локальные минимумы и выбрать наименьшее значение. В дальнейшем будем рассматривать задачу нахождения локального минимума.
Теорема 1 (необходимое условие экстремума)
Пусть есть точка локального минимума (максимума) функции f(x) на множестве и она дифференцируема в точке х*. Тогда градиент функции в точке х* равен нулю:
Теорема 2 (достаточное условие)
Пусть функция f(x) в точке х* дважды дифференцируема, ее градиент равен нулю, а матрица Гессе является положительно определенной (отрицательно определенной), т. е.
Тогда точка х* есть точка локального минимума (максимума) функции на множестве .
Для определения знака матрицы Гессе используется критерий Сильвестра.
Задание 1.1
Найти минимум функции классическим методом
, используя необходимые и достаточные условия.
Данную задачу будем решать для функции f(x 1 ,x 2).
Начальная точка x 0
; x 0 =(1.5,1.5)
Найдем частные производные первого порядка функции f(x):

![]()
![]() ; ; ;
; ; ;
Найдем производные второго порядка функции f(x):
Составим матрицу Гессе
![]()
Классифицируем матрицу Гессе, используя критерий Сильвестра:
Следовательно, матрица является положительно определенной.
Используя критерии проверки достаточных условий экстремума, можно сделать вывод: точка - является точкой локального минимума.
Значение функции в точке минимума:
![]() ;
;
Задание 1.2
Найти минимум данной функции методом градиентного спуска с дроблением шага.
Метод градиентного спуска с дроблением шага
Метод градиентного спуска является одним из самых распространенных и самых простых методов решения задачи безусловной оптимизации. Он основан на свойстве градиента функции, согласно которому направление градиента совпадает с направлением наискорейшего возрастания функции, а направление антиградиента – с направлением наискорейшего убывания функции. При решении задачи безусловной минимизации за направление спуска из точки x(m) выбирается
p(m) = –g(x(m)) = –f "(x(m)).
Таким образом, итерационная процедура для этого метода имеет вид
x(m+1) = x(m) – a(m)g(x(m)) (*)
Для выбора шага a(m) можно использовать процедуру дробления шага, которая состоит в следующем. Произвольно фиксируют начальное значение шага a(m) = a(m – 1) = a. Если в точке x(m+1), вычисленной в соответствии с (2.24), выполняется неравенство
f(x(m+1)) > f(x(m)),
то шаг дробится, например, пополам, т.е. полагается a(m +1) = 0.5a(m).
Применим метод градиентного спуска с дроблением шага для минимизации квадратичной функции
В результате решения данной задачи был найден минимум
x* = (-0.182; -0.091),
значение функции f(x*) = -0.091,
количество итераций n = 17.
Коэффициент
корреляции, предложенный во II–й
половине XIX
века Г. Т. Фехнером, является наиболее
простой мерой связи между двумя
переменными. Он основан на сопоставлении
двух психологических признаков x
i
и y
i
,
измеренных на одной и той же выборке,
по сопоставлению знаков отклонений
индивидуальных значений от среднего:
и .
Вывод о корреляции между двумя переменными
делается на основании подсчета числа
совпадений и несовпадений этих знаков.
.
Вывод о корреляции между двумя переменными
делается на основании подсчета числа
совпадений и несовпадений этих знаков.
Пример
Пусть x i и y i – два признака, измеренные на одной и той же выборке испытуемых. Для вычисления коэффициента Фехнера необходимо вычислить средние значения для каждого признака, а также для каждого значения переменной – знак отклонения от среднего (табл. 8.1):
Таблица 8.1
|
x i |
y i |
|
|
Обозначение |
|


В таблице: а – совпадения знаков, b – несовпадения знаков; n a – число совпадений, n b – число несовпадений (в данном случае n a = 4, n b = 6).
Коэффициент корреляции Фехнера вычисляется по формуле:
 (8.1)
(8.1)
В рассматриваемом случае:

Вывод
Между исследуемыми переменными существует слабая отрицательная связь.
Необходимо отметить, что коэффициент корреляции Фехнера не является достаточно строгим критерием, поэтому его можно использовать лишь на начальном этапе обработки данных и для формулировки предварительных выводов.
8. 4. Коэффициент корреляции Пирсона
Исходный принцип коэффициента корреляции Пирсона – использование произведения моментов (отклонений значения переменной от среднего значения):
Если сумма произведений моментов велика и положительна, то х и у связаны прямой зависимостью; если сумма велика и отрицательна, то х и у сильно связаны обратной зависимостью; наконец, в случае отсутствия связи между x и у сумма произведений моментов близка к нулю.
Для того чтобы статистика не зависела от объема выборки, берется не сумма произведений моментов, а среднее значение. Однако деление производится не на объем выборки, а на число степеней свободы n - 1.
Величина
 является мерой связи междух
и у
и называется ковариацией х
и у
.
является мерой связи междух
и у
и называется ковариацией х
и у
.
Во многих задачах естественных и технических наук ковариация является вполне удовлетворительной мерой связи. Ее недостатком является то, что диапазон ее значений не фиксирован, т. е. она может варьировать в неопределенных пределах.
Для того чтобы стандартизировать меру связи, необходимо избавить ковариацию от влияния стандартных отклонений. Для этого надо разделить S xy на s x и s y:
 (8.3)
(8.3)
где r xy - коэффициент корреляции, или произведение моментов Пирсона.
Общая формула для вычисления коэффициента корреляции выглядит следующим образом:

 (некоторые преобразования)
(некоторые преобразования)

 (8.4)
(8.4)
Влияние преобразования данных на r xy:
1. Линейные преобразования x и y типа bx + a и dy + c не изменят величину корреляции между x и y .
2. Линейные преобразования x и y при b < 0, d > 0, а также при b > 0 и d < 0 изменяют знак коэффициента корреляции, не меняя его величины.
Достоверность (или, иначе, статистическая значимость) коэффициента корреляции Пирсона может быть определена разными способами:
По таблицам критических значений коэффициентов корреляции Пирсона и Спирмена (см. Приложение, табл. XIII). Если полученное в расчетах значение r xy превышает критическое (табличное) значение для данной выборки, коэффициент Пирсона считается статистически значимым. Число степеней свободы в данном случае соответствует n – 2, где n – число пар сравниваемых значений (объем выборки).
По таблице XV Приложений, которая озаглавлена «Количество пар значений, необходимое для статистической значимости коэффициента корреляции». В данном случае необходимо ориентироваться на коэффициент корреляции, полученный в вычислениях. Он считается статистически значимым, если объем выборки равен или превышает табличное число пар значений для данного коэффициента.
По коэффициенту Стьюдента, который вычисляется как отношение коэффициента корреляции к его ошибке:
 (8.5)
(8.5)
 Ошибка
коэффициента корреляции
вычисляется по
следующей формуле:
Ошибка
коэффициента корреляции
вычисляется по
следующей формуле:
где m r - ошибка коэффициента корреляции, r - коэффициент корреляции; n - число сравниваемых пар.
Рассмотрим порядок вычислений и определение статистической значимости коэффициента корреляции Пирсона на примере решения следующей задачи.
Условие задачи
22 старшеклассника были протестированы по двум тестам: УСК (уровень субъективного контроля) и МкУ (мотивация к успеху). Получены следующие результаты (табл. 8.2):
Таблица 8.2
|
УСК (x i ) |
МкУ (y i ) |
УСК (x i ) |
МкУ (y i ) |
||
Задание
Проверить гипотезу о том, что для людей с высоким уровнем интернальности (балл УСК) характерен высокий уровень мотивации к успеху.
Решение
1. Используем коэффициент корреляции Пирсона в следующей модификации (см. формулу 8.4):

Для удобства обработки данных на микрокалькуляторе (в случае отсутствия необходимой компьютерной программы) рекомендуется оформление промежуточной рабочей таблицы следующего вида (табл. 8.3):
Таблица 8.3
|
x i y i |
||||
|
x 1 y 1 x 2 y 2 x 3 y 3 x n y n |
||||
|
Σx i y i |
2. Проводим вычисления и подставляем значения в формулу:

3. Определяем статистическую значимость коэффициента корреляции Пирсона тремя способами:
1-й способ:
В табл. XIII Приложений находим критические значения коэффициента для 1-го и 2-го уровней значимости: r кр. = 0,42; 0,54 (ν = n – 2 = 20).
Делаем вывод о том, r xy > r кр . , т. е. корреляция является статистически значимой для обоих уровней.
2-й способ:
Воспользуемся табл. XV, в которой определяем число пар значений (число испытуемых), достаточное для статистической значимости коэффициента корреляции Пирсона, равного 0,58: для 1-го, 2-го и 3-го уровней значимости оно составляет, соответственно, 12, 18 и 28.
Отсюда мы делаем вывод о том, что коэффициент корреляции является значимым для 1-го и 2-го уровня, но «не дотягивает» до 3-го уровня значимости.
3-й способ:
Вычисляем ошибку коэффициента корреляции и коэффициент Стьюдента как отношение коэффициента Пирсона к ошибке:
В табл. X находим стандартные значения коэффициента Стьюдента для 1-го, 2-го и 3-го уровней значимости при числе степеней свободы ν = n – 2 = 20: t кр. = 2,09; 2,85; 3,85.
Общий вывод
Корреляция между показателями тестов УСК и МкУ является статистически значимой для 1-го и 2-го уровней значимости.
Примечание:
При интерпретации коэффициента корреляции Пирсона необходимо учитывать следующие моменты:
Коэффициент Пирсона может использоваться для различных шкал (шкала отношений, интервальная или порядковая) за исключением дихотомической шкалы.
Корреляционная связь далеко не всегда означает связь причинно-следственную. Другими словами, если мы нашли, предположим, положительную корреляцию между ростом и весом у группы испытуемых, то это вовсе не означает, что рост зависит от веса или наоборот (оба этих признака зависят от третьей (внешней) переменной, каковая в данном случае связана с генетическими конституциональными особенностями человека).
r xu » 0 может наблюдаться не только при отсутствии связи между x и y , но и в случае сильной нелинейной связи (рис. 8.2 а). В данном случае отрицательная и положительная корреляции уравновешиваются и в результате создается иллюзия отсутствия связи.
r xy может быть достаточно мал, если сильная связь между х и у наблюдается в более узком диапазоне значений, чем исследуемый (рис. 8.2 б).
Объединение выборок с различными средними значениями может создавать иллюзию достаточно высокой корреляции (рис. 8.2 в).
y i y i y i
|
+ + . . |
x i x i x i
Рис. 8.2. Возможные источники ошибок при интерпретации величины коэффициента корреляции (объяснения в тексте (пункты 3 – 5 примечания))
Для устранения недостатка ковариации был введён линейный коэффициент корреляции (или коэффициент корреляции Пирсона), который разработали Карл Пирсон, Фрэнсис Эджуорт и Рафаэль Уэлдон (англ.)русск. в 90-х годах XIX века. Коэффициент корреляции рассчитывается по формуле :
где ![]() ,
, ![]() -
среднее значение выборок.
-
среднее значение выборок.
Коэффициент корреляции изменяется в пределах от минус единицы до плюс единицы .
Коэффициент ранговой корреляции Кендалла
Применяется для выявления взаимосвязи между количественными или качественными показателями, если их можно ранжировать. Значения показателя X выставляют в порядке возрастания и присваивают им ранги. Ранжируют значения показателя Y и рассчитывают коэффициент корреляции Кендалла:
![]() ,
,
большим значением рангов Y.
Суммарное число наблюдений, следующих за текущими наблюдениями с меньшим значением рангов Y. (равные ранги не учитываются!)
Коэффициент ранговой корреляции Спирмена
Степень зависимости двух случайных величин (признаков) X и Y может характеризоваться на основе анализа получаемых результатов . Каждому показателю X и Y присваивается ранг. Ранги значений X расположены в естественном порядке i=1, 2, . . ., n. Ранг Y записывается как Ri и соответствует рангу той пары (X, Y), для которой ранг X равен i. На основе полученных рангов Х i и Yi рассчитываются их разности и вычисляется коэффициент корреляции Спирмена:
![]()
Значение коэффициента меняется от −1 (последовательности рангов полностью противоположны) до +1 (последовательности рангов полностью совпадают). Нулевое значение показывает, что признаки независимы.
Коэффициент корреляции знаков Фехнера
Подсчитывается количество совпадений и несовпадений знаков отклонений значений показателей от их среднего значения.
C - число пар, у которых знаки отклонений значений от их средних совпадают.
H - число пар, у которых знаки отклонений значений от их средних не совпадают.
Литература: http://ru.wikipedia.org/wiki/%CA%EE%F0%F0%E5%EB%FF%F6%E8%FF
9. вычислите коэффициент корреляции Спирмэна.
Оценка взаимосвязи показателей: X – место занятое в стрельбе из винтовки; Y – количество попаданий в десятку. Все прочие условия примерно одинаковы. Результаты соревнований представлены в Таблице №1
Таблица №1 Расчет рангового коэффициента корреляции Спирмэна.
Пояснение:
шаг 1. Проранжировать (упорядочить и приписать порядковые номера) показатели X и Y. Так как X упорядочен и обозначает соответствующие ранги, перепишем его в столбец 3. показателю Y приписываем ранги следующим образом: значению 10 – ранг 1; 9 – ранг (2+3)/2=2,5; 8 – ранг 4; 7 – ранг 5 и т. д. (столбец 4)
шаг 2. вычислить разность рангов d=Dx-Dy(столбец 5)
шаг 3. вычислить квадрат разности d=(Dx-Dy)2 (столбец 6)
шаг 4. вычислить сумму квадратов разности
Следует упомянуть коэффициент Фехнера, характеризующий элементарную степень тесноты связи, который целесообразно использовать для установления факта наличия связи, когда существует небольшой объем исходной информации.
Он основан на сравнении поведения отклонений индивидуальных значений каждого признака ( и ) от своей средней величины. При этом во внимание принимаются не величины отклонений ![]() , а их знаки («+» или «-»). Определив знаки отклонения от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений () и несовпадений ().
, а их знаки («+» или «-»). Определив знаки отклонения от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений () и несовпадений ().
Коэффициент Фехнера ()рассчитывается как отношение разности чисел пар совпадений и несовпадений знаков к их сумме, т.е. к общему числу наблюдаемых единиц:
![]() . (9.12)
. (9.12)
Очевидно, что если знаки всех отклонений по каждому признаку совпадают, то и тогда . Это характеризует наличие прямой связи. Если все знаки не совпадают, то , а , что характеризует обратную связь. Коэффициент Фехнера, как и любой другой показатель тесноты связи, может принимать значения от -1 до +1.
Пример 9.3 . Имеются следующие данные о росте восьми пар братьев и сестер (таблица 9.2).
Таблица 9.2 - Данные о росте восьми пар братьев и сестер
| Рост брата, см | Рост сестры, см |
Определить тесноту зависимости между ростом братьев и сестер на основе:
а) коэффициента Фехнера;
б) коэффициентов корреляции рангов Спирмэна и Кендэла.
Решение:
а) Рассчитаем средние величины и :
Определив знаки отклонения от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений () и несовпадений ():
![]() .
.
Коэффициент Фехнера ()рассчитывается по формуле 9.8:
![]() .
.
По величине коэффициента Фехнера () можно сделать вывод о весьма тесной зависимости между и .
б) По уже имеющимся данным (графы 1-2 таблицы 9.2) для нахождения коэффициентов корреляции рангов Спирмэна и Кендэла построим таблицу 9.3.
Таблица 9.3 – Расчетные значения, необходимые для исчисления коэффициентов корреляции рангов Спирмэна и Кендэла
| Подсчет баллов | |||||||
| «+» | «-» | ||||||
| 6,5 6,5 | 1,5 1,5 6,5 6,5 | -0,5 -1 -2 2,5 -0,5 -1,5 | 0,25 6,25 0,25 2,25 | - | - | ||
В данном примере отдельные значения и повторяются. При ранжировании повторяющихся значений, им присваивается ранг, рассчитанный как средняя арифметическая из суммы мест, которые они занимают по возрастанию.
Расчет рангов показан в графах 3 и 4.
Для случая повторяющихся рангов есть особые скорректированные формулы и для коэффициента Спирмэна, и для коэффициента Кендэла. Однако на практике часто пользуются приведенной ранее формулой Спирмэна и для случая повторяющихся рангов, поскольку ошибку она дает весьма малую:
 .
.
Формула коэффициента Кендэла для повторяющихся рангов имеет вид:
 ,
,
где , как и раньше, a и -показатели, корректирующие максимальную сумму баллов и определяемые по формуле , где - число повторяющихся рангов в соответствующем ряду и :
Так как значения рангов идут строго в возрастающем порядке, то следим лишь за поведением . После первой пары значений рангов, где в шести случаях идут значения и ни одного случая, где . Это означает, что в графу 7 мы ставим число «6», а в графу 8число «0». Далее после второй пары значений рангов, где в четырех случаях идут значения и ни одного случая, где . Это означает, что в графу 7 мы ставим число «4», а в графу 8число «0». ». В случае, если бы после второй пары значений рангов, где в трех случаях шли бы значения и два случая, где - это означало бы, что в графу 7 мы ставим число «3», а в графу 8число «2» и т.д.
Расчет и показан в графах 7 и 8. По результатам подсчетов .
Отсюда коэффициент корреляции рангов Кендэла:
По величине коэффициента () можно сделать вывод о весьма тесной зависимости между и , т.е. рост сестры весьма зависим от роста её брата.
Говоря о расчете коэффициента Кендэла, следует еще раз подчеркнуть, что если наблюдаемые единицы совокупности записаны неупорядоченно по одному из признаков (таблица 9.2.), то после ранжирования значений и , ранги одного из признаков, например , следует переписать, расположив их строго в порядке возрастания (или убывания), а для второго признака сохранить значения рангов, соответствующие значениям каждого в исходных данных (таблица 9.3).
Коэффициент конкордации
Корреляция рангов ()может определяться не только для двух, но и для большего числа показателей (факторов). Исчисляемый в этом случае показатель именуется коэффициентом конкордации ()и рассчитывается по формуле:
 , (9.13)
, (9.13)
где - количество коррелируемых факторов;
Число наблюдений;
- сумма квадратов отклонений суммы рангов по факторам от их средней арифметической, т.е.
а)  или, что по значению тоже самое, (9.14)
или, что по значению тоже самое, (9.14)
б)  где - ранг -го показателя. (9.15)
где - ранг -го показателя. (9.15)
Коэффициент конкордации часто используется в экспертных оценках для определения согласованности мнений экспертов в распределение мест (рангов) между исследуемыми факторами или объектами по их приоритетности.
Пример 9.4. Пусть имеются следующие данные по пяти фирмам (графы 1-4 таблицы 9.4).
Таблица 9.4 – Исходные данные и промежуточные расчеты коэффициентов конкордации
| Фирма | Прибыль, тыс. руб. | Стоимость оборотных средств, млн. руб. | Затраты на 100 руб. продукции, руб. | Ранги факторов | Сумма рангов | Квадрат суммы рангов | ||
| 2,0 2,5 1,8 2,2 2,4 | ||||||||
| Σ |
Определить тесноту зависимости между с помощью коэффициента конкордации.
Решение:
1. Ранжираем каждый и трех показателей (графы 5-7).
2. Находим сумму рангов по каждой строке (графа 8) и общую сумму пяти строк
3. Возводим в квадрат сумму рангов в каждой строке и находим сумму пяти строк (графа 9):
 .
.
4. Находим , используя формулу 9.11:
![]() .
.
5. Рассчитаем коэффициент конкордации:
Учитывая малое значение коэффициента конкордации, можно сказать, что зависимость между рассматриваемыми показателями весьма незначительна.
Существуют и другие коэффициенты для измерения тесноты зависимости (коэффициенты ассоциации и контингенции ; коэффициент взаимной сопряженности Пирсона ; коэффициент Чупрова ), которые применяются достаточно редко.
Непараметрические методы
Применение корреляционного и регрессионного анализа требует, чтобы все признаки были количественно измеренными. Построение аналитических группировок предполагает, что количественным должен быть результативный признак. Параметрические методы основаны на использовании основных количественных параметров распределения (средних величин и дисперсий).
Вместе с тем в статистике применяются также непараметрические методы , с помощью которых устанавливается связь между качественными (атрибутивными) признаками . Сфера их применения шире, чем параметрических, поскольку не требуется соблюдения условия нормальности распределения зависимой переменной, однако при этом снижается глубина исследования связей. При изучении зависимости между качественными признаками не ставится задача представления ее уравнением. Здесь речь идет только об установлении наличия связи и измерении ее тесноты.
В практике статистических исследований приходится иногда анализировать связи между альтернативными признаками , представленными только группами с противоположными (взаимоисключающими) характеристиками. Тесноту связи в этом случае можно оценить, вычислив коэффициент ассоциации.
Для расчета коэффициента ассоциации строится четырехклеточная корреляционная таблица, которая носит название таблицы «четырех полей» и имеет следующий вид:
| a | b | a+b |
| c | d | c+d |
| a+c | b+d | a+b+c+d |
Применительно к таблице «четырех полей» с частотами и коэффициент ассоциации выражается формулой:
 . (9.16)
. (9.16)
Коэффициент ассоциации изменяется от -1 до +1; чем ближе к +1 или -1, тем сильнее связаны между собой изучаемые признаки.
Если не менее 0,3, то это свидетельствует о наличии связи между качественными признаками.
Пример 9.5 . Имеющиеся данные о росте отцов и сыновей представлены в таблице 9.5.
Таблица 9.5 - Распределение отцов и сыновей по росту, чел.
| Рост сына | Рост отца | Всего | |
| Ниже среднего | Выше среднего | ||
| Ниже среднего | |||
| Выше среднего | |||
| Итого |
Подсчитаем коэффициент ассоциации по данным таблицы 9.5:
![]()
Поскольку , между ростом отцов и сыновей существует корреляционная связь.
Если по каждому из взаимосвязанных признаков выделяется число групп более двух, то для подобного рода таблиц теснота связи между качественными признаками может быть измерена с помощью показателя взаимной сопряженности А.A. Чупрова:
 (9.17)
(9.17)
где - число возможных значений первой статистической величины (число групп по столбцам);
Число возможных значений второй статистической величины (число групп по строкам);
Показатель взаимной сопряженности (определяется как сумма отношений квадратов частот клетки таблицы распределения к произведению итоговых частот соответствующего столбца и строки).
Вычтя из этой суммы единицу, получим .
Коэффициент взаимной сопряженности А.А. Чупрова изменяется от 0 до 1, но уже при значении 0,3 можно говорить о тесной связи между вариацией изучаемых признаков.
Пример 9.6. Данные об уровне образования членов 100 семей приведены в таблице 9.6.
Таблица 9.6- Распределение семей по уровню образования мужа и жены
Примечание: частоты - верхние строки; их квадраты (в скобках) - средние строки; квадраты частот, деленные на суммы частот по столбцу - нижние строки; в итоговых столбцах - сумма частот, сумма результатов деления (А), а также результат деления нижнего числа на верхнее - последний столбец (В).
Тогда ![]() , .
, .
Коэффициент взаимной сопряженности А.А. Чупрова:
 .
.
Его значение показывает заметную связь между уровнями образования мужа и жены при формировании семьи.
И некоторые ранговые коэффициенты
Кроме рассмотренных в подразд. 10.2 коэффициента кор-
Реляции, коэффициента детерминации, корреляционного от-
Ношения, существуют и другие коэффициенты для оценки
Степени тесноты корреляционной связи между изучаемыми
Явлениями, причем формулы для их нахождения достаточно
Просты. Рассмотрим некоторые из таких коэффициентов.
Коэффициент корреляции знаков Фехнера
Этот коэффициент является простейшим показателем
Степени тесноты связи, он был предложен немецким ученым
Г. Фехнером. Данный показатель основан на оценке степени
Согласованности направлений отклонений индивидуальных
Значений факторного и результативного признаков от соот-
Ветствующих средних значений. Для его определения вычис-
Ляют средние значения результативного () и факторного ()
Признаков, а затем находят знаки отклонений от средних для
Всех значений результативного и факторного признаков. Если
сравниваемое значение больше среднего, то ставится знак “+”,
а если меньше - знак “-”. Совпадение знаков по отдельным
значениям рядов x и y означает согласованную вариацию, а их
Несовпадение - нарушение согласованности.
Коэффициент Фехнера находится по следующей формуле:
, (10.40)
где С - число совпадений знаков отклонений индивидуаль-
Ных значений от средней величины;
Н - число несовпадений знаков отклонений индивидуаль-
Ных значений от средней величины.
Заметим, что -1 ≤ Кф ≤ 1. При Кф = ±1 имеем полную пря-
мую или обратную согласованность. При Кф = 0 - связь между
Рядами наблюдений отсутствует.
По исходным данным примера 10.1 рассчитаем коэффици-
Ент Фехнера. Необходимые данные для его определения помес-
тим в табл. 10.4.
Из табл. 10.4 находим, что С = 6; Н = 0, поэтому по форму-
ле (10.40) получаем: , т. е. полную прямую зависимость
между хищениями оружия (х ) и вооруженными преступлени-
ями (y ). Полученное значение Кф подтверждает вывод, сделан-
Ный после вычисления коэффициента корреляции о том, что
Между рядами x и y существует достаточно близкая прямая
Линейная зависимость.
Таблица 10.4
Хищение
оружия, x
Вооруженные
преступления, y
Знаки отклонения от средней
773 4481 − −
1130 9549 − −
1138 8873 − −
1336 12160 + +
1352 18059 + +
1396 19154 + +
Коэффициент корреляции рангов Спирмэна
Данный коэффициент относится к ранговым, т. е. коррели-
Руются не сами значения факторного и результативного при-
Знаков, а их ранги (номера их мест, занимаемых в каждом ряду
Значений по возрастанию или убыванию). Коэффициент кор-
Реляции рангов Спирмэна основан на рассмотрении разности
Рангов значений факторного и результативного признаков. Для
его нахождения используется следующая формула:
, (10.41)
Где - квадрат разности рангов.
Рассчитаем коэффициент Спирмэна по данным рассмат-
Риваемого примера 10.1. Так как значение факторного призна-
ка х мы изначально расположили по возрастанию, то ряд х ран-
жировать не надо. Ранжируем (от меньшего к большему) ряд y .
Все необходимые данные для расчета помещены в табл. 10.5.
Таблица 10.5
Ранги Rgx ряда х Ранги Rgy ряда y |di | = |Rgxi − Rgyi |
Теперь по формуле (10.41) получаем
Заметим, что -1 ≤ ρc ≤ 1, т. е. полученное значение показыва-
Ет, что между хищениями оружия и вооруженными преступле-
Открытие бизнеса

Где можно и где нельзя работать после туберкулеза Где можно работать после
Форекс
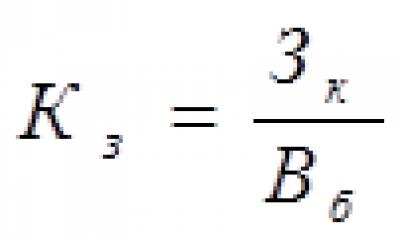
Направления повышения эффективности использования собственного капитала На базе двигателя с плоским печатным якорем разработаны изделия для автомобильной промышленности
Банки




