Для грамотного использования Oracle необходимо иметь хорошее понимания языка SQL . Курс "Oracle. Программирование на SQL, PL/SQL и Java " раскрывает полный спектр возможностей языка SQL в Oracle и ряд аспектов неочевидных особенностей построения типовых конструкций БД.
- PL/SQL - процедурный язык , разработанный фирмой Oracle для написания хранимых в БД подпрограмм. PL/SQL обеспечивает общую основу процедурного программирования как в клиентских приложениях, так и на стороне сервера, в том числе хранимых на сервере подпрограмм, пакетов и триггеров базы данных.
- Java - объектный язык , который может использоваться для работы с Oracle в самых разных конфигурациях, в том числе, благодаря встроенной в Oracle Java-машине, в качестве второго языка для хранимых процедур. Java не зависит от конкретных платформ и может служить эффективным средством интеграции БД Oracle с другими приложениями, в том числе в Internet.
Курс сопровождается практическими упражнениями, позволяющими закрепить понимание базовых понятий и освоить основные технические приемы программирования на языках SQL, PL/SQL и Java.
По окончании курса слушатели получают возможность самостоятельного программирования Oracle на этих трех языках для решения задач разработки приложений в архитектуре клиент-сервер и в трехзвенной архитектуре, а также задач администрирования БД.
Основное отличие этого курса от ряда других со схожей тематикой в том, что целью ставится научить конкретных слушателей реальной работе с Oracle на этих языках, а не прочитать формально программу, подготовленную третьей стороной.
Курс предназначен для разработчиков, программистов и администраторов баз данных. Слушатели должны обладать хорошим уровнем компьютерной грамотности, и иметь опыт программирования.
Знания даются по следующим версиям:
- Oracle Database 8i
- Oracle Database 9i
- Oracle Database 10g
- Oracle Database 11g
- Oracle Database 12c
Программа курса "Oracle. Программирование на SQL, PL/SQL и Java"
Введение в Oracle SQL
1. Основные понятия
- Базы данных и реляционная модель
- Базы данных
- Реляционный подход к моделированию данных
- Реализация реляционной СУБД
Другие подходы к моделированию данных и другие типы СУБД - Что такое SQL ?
- История и стандарты
- Oracle-диалект SQL
- PL/SQL
2. SQL*Plus и ввод предложений на SQL
3. Пример "схемы" базы данных
4. Создание, удаление таблиц и изменение структуры
- Предложение CREATE TABLE
- Типы данных в столбцах
- Уточнения в описаниях столбцов
- Указание NOT NULL
- Значения по умолчанию
- Проверка CHECK поступающих в таблицу значений
- Создание таблиц по результатам запроса к БД
- Именование таблиц и столбцов
- Виртуальные столбцы
- Удаление таблиц
- Изменение структуры таблиц
- Логические и технические особенности удаления столбца
- Использование синонимов для именования таблиц
- Переименования
- Справочная информация о таблицах в БД
5. Основные элементы предложений DML: выражения
- Непосредственные значения данных (литералы)
- Числовые значения
- Строки текста
- Моменты и интервалы времени
- "Системные переменные"
- Числовые выражения
- Выражения над строками текста
- Выражения над типом "момент времени"
- Функции
- Скалярные функции
- CASE-выражения
- Скалярный запрос
- Условные выражения
- Отдельные замечания по поводу отсутствия значения в выражениях
6. Выборка данных
- Фразы предложения SELECT
- Общие правила построения предложения SELECT
- Порядок обработки предложения SELECT
- Пример 1 предложения SELECT
- Пример 2 предложения SELECT
- Логическая целостность обработки предложения SELECT
- Фраза FROM предложения SELECT
- Варианты указания столбца
- Столбцы из разных таблиц
- Использование псевдонимов в запросе
- Подзапрос в качестве источника данных
- Специальный случай для запроса-соединения
- Фраза WHERE предложения SELECT
- Общий алгоритм отработки фразы WHERE
- Операторы сравнения для получения условного выражения
- Связки AND, OR и NOT для комбинирования условных выражений
- Условный оператор IS
- Условный оператор LIKE
- Условный оператор BETWEEN
- Условный оператор IN с явно перечисляемым множеством
- Условный оператор IN с множеством, получаемым из БД
- Условия сравнения с подзапросом
- Указание ANY и ALL для сравнения с элементами множества значений
- Условный оператор EXISTS
- Фраза SELECT и функции в предложении SELECT
- Сокращенная запись для группового отбора столбцов
- Выражения во фразе SELECT
- Подзапросы во фразе SELECT
- Уточнение DISTINCT
- Особенности поведения стандартных агрегатных функций в предложении SELECT
- Именование столбцов в результате запроса
- Системная функция ("переменная") ROWNUM и особенности ее использования
- Аналитические функции
- Выражение типа ссылка на курсор
- Фраза ORDER BY предложения SELECT
- Простейшая сортировка
- Упорядочение по значению выражения
- Указание номера столбца
- Двоичное и "языковое" упорядочение строк
- Особенности обработки отсутствующих значений (NULL)
- Фразы GROUP BY и HAVING предложения SELECT
- Пример отработки фразы GROUP BY … HAVING
- Отсутствие значения в выражении для группировки
- Другие примеры
- Указание ROLLUP, CUBE и GROUPING SETS в во фразе GROUP BY
- Фраза CONNECT BY предложения SELECT
- Специальные системные функции в предложениях с CONNECT BY
- Упорядочение результата
- Фраза WITH предварительной формулировки подзапросов
- Комбинирование предложений SELECT
- Комбинирование оператором UNION
- Комбинирование оператором INTERSECT
- Комбинирование оператором MINUS
- Подзапросы
- Операция соединения в предложении SELECT
- Виды соединений
- Новый синтаксис в версии 9
- Особенности выполнения операции соединения
7. Обновление данных в таблицах
- Добавление новых строк
- Явное добавление строки
- Добавление строк, полученных подзапросом
- Добавление в несколько таблиц одним оператором
- Изменение существующих значений полей
- Использование умолчательных значений в INSERT и UPDATE
- Удаление строк из таблицы
- Выборочное удаление
- Вариант полного удаления
- Комбинирование UPDATE, INSERT и DELETE в одном операторе
- Логическая целостность операторов обновления данных таблиц и реакция на ошибки
- Реакция на ошибки в процессе исполнения
- Фиксация изменений в БД
- Данные о системном номере изменения для строки
- Ускорение выполнения COMMIT
8. Быстрое обращение к прошлым значениям данных
- Чтение старых значений строк таблицы
- Восстановление таблиц и данных ранее удаленных таблиц
9. Схемные ограничения целостности
- Разновидности схемных ограничений целостности
- Ограничение NOT NULL
- Первичные ключи
- Уникальность значений в столбцах
- Внешние ключи
- Дополнительное условие для значения в поле строки
- Дополнительное условие, связывающее значения в нескольких полях строки
- Добавление ограничения при наличии нарушений
- Приостановка проверки схемных ограничений в пределах транзакции
- Отключение и включение схемных ограничений целостности
- Технология включения и выключения схемных ограничений целостности
- Более сложные правила целостности
10. Виртуальные таблицы (производные, выводимые: views)
- Основные ("базовые") и виртуальные таблицы
- Обновление виртуальных таблиц
- Ограничения прямой модификации данных через виртуальные таблицы
- Запрет непосредственных обновлений
- Сужение возможности непосредственных обновлений
- Виртуальные таблицы с хранием данных
- Особенности именованых виртуальных таблиц
- Неименованые виртуальные таблицы без хранения данных
11. Нескалярные типы для "сложно устроенных" данных в Oracle
- Хранимые объекты
- Простой пример
- Использование свойств и методов объектов
- Использование ссылок на объект
- Коллекции
- Вложенные таблицы
- Массивы VARRAY
- Тип XMLTYPE
- Простой пример
- Таблицы данных XMLTYPE
- Преобразование табличных данных в тип XMLTYPE
- Тип ANYDATA
12. Вспомогательные виды хранимых объектов
- Генератор уникальных номеров
- Каталог операционной системы
- Таблицы с данными временного хранения
- Ссылка на другую БД
- Подпрограммы
- Индексы
- Индексы для проверки схемных ограничений целостности
- Таблицы с внешним хранением данных
13. Некоторые замечания по оптимизации SQL-предложений
14. Транзакции и блокировки
- Транзакции в Oracle
- Примеры блокировок данных транзакциями
- Разновидности блокировок
- Неявные блокировки при операциях DML
- Влияние внешних ключей
- Явная блокировка таблиц (тип TM) командой LOCK
- Явная блокировка отдельных строк таблиц
- Недокументированная разновидность групповой блокировки
- Блокировки предложениями DDL
15. Пользователи (схемы) и дополнительные средства разграничения доступа к данным
16. Таблицы системного каталога (словаря-справочника)
18. Встроенный SQL
- Некоторые примеры составления запросов
19. Выдать сотрудников в соответствии с большим (меньшим) окладом
- Вопрос к БД
- "Очевидное", но неправильное решение
- Правильные решения
- Решение типа top-N (начиная с версии 8.1.5)
- Решение с использованием аналитических функций ранжирования
20. Переформулировка запроса с HAVING
22. Ловушка условия с отрицанием NOT
23. Ловушка в NOT IN (S)
Введение в PL/SQL
1. Основные понятия
- Место PL/SQL в архитектуре Oracle
- Общая структура программы на PL/SQL
2. Основные типы и структуры данных
- Скалярные переменные
- Числовые типы
- Строковые типы
- Моменты времени и интервалы
- Булевы переменные
- LOB-типы
- Объявление переменных и постоянных
- Записи
- Объявление записей в программе
- Присвоения
- Ссылка на типы уже имеющихся данных
- Пользовательские подтипы
3. Выражения
4. Основные управляющие структуры
- Ветвление программы
- Предложение IF-THEN
- Предложение IF-THEN-ELSE
- Предложение IF-THEN-ELSIF
- Предложения CASE
- Безусловная передача управления
- Циклы
- Простой цикл
- Счетный цикл (FOR)
- Цикл по курсору (FOR)
- Цикл WHILE
- Имитация цикла REPEAT UNTIL
- Метки в циклах и в блоках
5. Подпрограммы
- Локальные подпрограммы
- Переопределение «внешних» имен
- Предваряющие (forward) объявления
- Повторение имен на одном уровне (overloading)
- 6. Взаимодействие с базой данных: статический SQL
- Использование записей вместо (списка) скаляров
7. Регулирование изменений в БД
- Управление транзакциями
- Блокировки
- Автономные транзакции
8. Встроенный динамический SQL
- Операторы встроенного динамического SQL
- Сравнительный пример двух способов работы с динамическим SQL
9. Использование курсоров
- Явные курсоры
- Объявление явных курсоров
- Открытие явных курсоров
- Извлечение результата через явный курсор
- Закрытие явного курсора
- Отсутствие запрета изменений таблиц при открытом курсоре
- Атрибуты для явных курсоров
- Несколько примеров использования циклов и курсоров
- Курсоры с блокировкой строк таблицы
- Предложение SELECT … FOR UPDATE
- Предосторожности употребления курсоров с блокировкой
- Возможность изменять строки, выбираемые курсором
- Ссылки на курсор
- Общие сведения
- Пример употребления для структуризации программы
- Неявные курсоры
10. Обработка исключительных ситуаций
- Объявление исключительных ситуаций
- Примеры обработки
- Порождение исключительных ситуаций
- Зона действия и распространение
- «Внутренние» исключительные ситуации блока
- Использование функций SQLCODE и SQLERRM
11. Хранимые процедуры и функции
- Общий синтаксис
- Параметры
- Тип параметра
- Режим использования параметра
- Значения по умолчанию
- Способы указать фактические значения параметрам
- Обращение к параметрам и к локальным переменным в теле подпрограммы
- Указания компилятору при создании подпрограмм
- Хранимые подпрограммы и привилегии доступа к данным в БД
- Две логики реализации привилегий доступа к данным БД
- Особенности передачи привилегий через роли
12. Триггерные процедуры
- Создание триггерной процедуры
- Отключение триггерных процедур
- Триггерные процедуры для событий категории DML
- Комбинированные триггерные процедуры
- Управление транзакциями в теле триггерной процедуры
- Последовательность срабатывания триггерных процедур, когда их несколько
- Триггерные процедуры INSTEAD OF для выводимых таблиц
- Триггерные процедуры для событий категории DDL
- Триггерные процедуры для событий уровня схемы и БД
13. Пакеты в PL/SQL
- Общая структура пакета
- Обращение к элементами пакета
- (Глобальные) данные пакета
- Взаимные вызовы и повторения имен
- Инициализация пакета
- Прагма SERIALLY_REUSABLE
14. Вызов функций PL/SQL в предложениях SQL
- Требования и ограничения на применение функций пользователей в SQL
- Обращение в SQL к функциям из состава пакетов
- Разрешение конфликта имен столбцов и функций
- Табличные функции в SQL
15. Более сложные типы данных: коллекции
- Синтаксис объявления типов для коллекций
- Работа с ассоциативными массивами
- Создание вложенной таблицы и массива VARRAY в программе
- Добавление и убирание элементов в коллекциях
- Множественные действия с коллекциями
- Преобразования коллекций
- Методы для работы с коллекциями в программе
- Примеры использования коллекций в программе
- Привилегии
- Серийное выполнение и привязывание запросов к массивам
- Серийное выполнение однотипных операций: конструкция FORALL
- Привязка массивами: конструкция BULK COLLECT INTO
- Пример для схемы SCOTT
- Использование коллекций в табличных функциях (потоковой реализации)
- Простой пример
- Использование для преобразования данных
16. Отладка процедур в PL/SQL
- Таблицы словаря-справочника
- Зависимости подпрограмм
- Системные пакеты
- Пакет DBMS_PROFILER
- Пакет DBMS_TRACE
- Функции пакета DBMS_UTILITY
- Пакет DBMS_DEBUG
- Пример построения профиля работы программы
17. Системы программирования для PL/SQL
18. Системные пакеты PL/SQL
- Пакеты STANDARD и DBMS_STANDARD
- Прочие системные пакеты
- Запись данных из программы в файл и обратно
- Шифрование данных
- Автоматический запуск заданий в Oracle
- Управление динамическим размещением объектов в библиотечном буфере
- Манипулирование большими неструктурированными объектами NULL
- Доступ к старым значениям данных
- Рассылка сообщений из программы на PL/SQL
- Возможности работы в PL/SQL с COM Automation
- Дополнительные сведения
- Простой пример разделения открытия курсора и обработки
- Более сложный пример разделения работы
20. Атрибуты триггерных процедур уровня схемы БД и событий в СУБД
ВВЕДЕНИЕ В ПРОГРАММИРОВАНИЕ ORACLE НА JAVA
1. Основные понятия
- Место Java в архитектуре Oracle
- Соотношение и взаимосвязь PL/SQL и Java в Oracle
2. Особенности Java и среда работы программ на Java
- Архитектура Java
- Программные компоненты в среде разработки на Java
- Установка среды разработки для Java
- Среда окружения OC
3. Создание самостоятельных программ на Java
- Пример транслирования и выполнения программы
4. Создание хранимых программ на Java в Oracle
- Дополнительные компоненты СУБД Oracle для работы с хранимыми программами на Java
- Ограничения на хранимые программы на Java
- Установка, удаление и обновление JServer/OJVM
- Пример создания хранимой Java-программы
- Создание с помощью loadjava
- Создание SQL-предложением
- Обращение к загруженному классу
- Работа со словарем-справочником
- Организация справочной информации
- Просмотр Java-элементов
- Просмотр исходных текстов
- Преобразование имен
- Особенности встроенной JVM
- Интерпретатор ojvmjava
5. Элементы программирования на Java
- Основы языка
- Базовые конструкции языка
- Переменные
- Операторы
- Выражения, предложения и блоки
- Передача управления
- Объекты и простые структуры
- Классы и наследование
- Создание классов
- Механика использования класса в программе
- Наследование
- Интерфейсы
- Обработка исключительных ситуаций
- Некоторые приемы программирования на Java
- Графический интерфейс
- Группы объектов (коллекции)
- Потоковый ввод и вывод
- Параметризация работы программы с помощью наборов свойств
- Сериализуемость объектов
6. Взаимодействие с базой данных через JDBC
- Использование JDBC
- JDBC и JDBC-драйверы
- JDBC-драйверы в Oracle
- Установка JDBC-драйверов для работы с Oracle
- Программа на Java для проверки связи через JDBC
- Работа с данными Oracle из внешних программ на Java
- Обращение к БД через толстый OCI-драйвер
- Работа с данными Oracle из хранимых программ на Java
- Обращение к БД через толстый драйвер («родной», kprb)
- Обращение к БД через тонкий драйвер
- Обращение к данным из триггерных процедур Oracle
7. Дополнительные свойства протокола JDBC
- Соединение с СУБД с помощью техники DataSource
- Простой пример соединения техникой DataSource
- Пример соединения с использованием службы JNDI
- Пример кеширования соединений
- Примеры организации логических соединений
- Изменение данных в БД и обращение ко хранимым подпрограммам
- Изменение данных
- Управление транзакциями
- Обращение к хранимым программам
- Параметризация запросов
- Использование типов данных Oracle
- Повышение эффективности обращений к БД
- Повторяющиеся запросы
- Пакетное выполнение
- Ссылка из программы на курсор в СУБД
8. Взаимодействие с базой данных через SQLJ
- Простой пример программы
- Транслирование и выполнение программы с SQLJ
- Более сложный пример: множественная выборка из БД
- Использование SQLJ в хранимых процедурах на Java
- Пример с загрузкой извне
- Пример с внутренней трансляцией
9. Основы построения приложений для web с помощью Java и Oracle
- Клиентская часть: работа с аплетами
- Пример транслирования и выполнения аплета
- Web-сервер Apache
- Общение с web-сервером по протоколу HTTP
- Общие понятия обмене сообщениями в HTTP
- Организация диалога в HTML
- Работа с сервлетами Java
- Общие сведения о сервлетах Java и о контейнерах сервлетов
- Устройство сервлета Java
- Пример составления сервлета на Java
- Пример обращения к сервлету
- Пример сервлета с обращением к базе данных
- Использование класса HttpServlet
- Работа с JavaServer Pages
- Пример составления страницы JSP
- Пример обращения к странице JSP
- Некоторые возможности построения страниц JSP
- Способы обращение к БД из страницы JSP
- Модель MVC организации приложения для web
10. Взаимодействие компонентов приложения для web
- Передача управления компонентов приложения web друг другу
- Обращение на страницах HTML к страницам JavaServer и сервлетам
- Передача управления со страниц JavaServer
- Передача управления компонентам web из сервлетов
- Абстракции Java для построения приложения web
- Запрос и ответ
- Область действия (scope)
- Контекст сервлета
- Предопределенные объекты страницы JavaServer
- Передача данных компонентов приложения web друг другу
- Передача данных через параметры запроса
- Передача данных через контекст и компоненты JavaBeans
11. Пример построения приложения для web средствами Java и Oracle
- Страница Logon.html
- Сервлет Logon
- Страница LogonError.html
- Страница Main.jsp
- Страница CompanyData.jsp и класс orajava.demos.StuffData
- Сервлет Logout
- Транслирование классов, размещение файлов и проверка приложения
- Дополнительные сведения
12. Пример программирования собственной разметки JSP
- Пример использования готовой разметки
- Пример программирования собственной разметки
В конце обучения на курсе проводится итоговая аттестация в виде теста или на основании оценок за практические работы, выполненных в процессе обучения.
В современном мире сложно обойтись без информационных технологий и их производных - компьютеров, мобильных телефонов, интернета и т.д., особенно в крупных компаниях и государственных организациях, работающих с большим количеством людей, а не только с парой VIP-клиентов, как это может быть в случае небольшой компании. А там, где есть большое количество контрагентов, заявителей и т.д. - не обойтись без баз данных, необходимых для обработки информации. Естественно, что времена гроссбухов и карточек, памятных многим по библиотекам, давно прошли, сегодня используются персональные компьютеры и электронные базы данных.
Сегодня невозможно представить работу крупнейших компаний, банков или государственных организаций без использования баз данных и средств Business Intelligence . Базы данных позволяют нам хранить и получать доступ к большим объемам информации, а система управления базами данных (СУБД) - осуществлять менеджмент доступных хранилищ информации.
В Учебном центре « Интерфейс» Вы научитесь эффективно использовать системы управления базами данных: быстро находить нужную информацию, ориентироваться в схеме базы данных, создавать запросы, осуществлять разработку и создание баз данных.
Обучение позволит Вам не только получить знания и навыки, но и подтвердить их, сдав соответствующие экзамены на статус сертифицированного специалиста. Опытные специалисты по СУБД Microsoft SQL Server или Oracle могут быть заинтересованы в изучении систем бизнес-аналитики. Это задачи достаточно сложные, использующие громоздкий математический аппарат, но они позволяют не только анализировать происходящие процессы, но и делать прогнозы на будущее, что востребовано крупными компаниями. Именно поэтому специалисты по бизнес-аналитике востребованы на рынке, а уровень оплаты их труда весьма и весьма достойный, хотя и квалифицированным специалистам по базам данных, администраторам и разработчикам, жаловаться на низкий уровень дохода тоже не приходится. Приходите к нам на курсы и получайте востребованную и высокооплачиваемую профессию. Мы ждем Вас!
В конце обучения на курсах проводится итоговая аттестация в виде теста или путём выставления оценки преподавателем за весь курс обучения на основании оценок, полученных обучающимся при проверке усвоения изучаемого материала на основании оценок за практические работы, выполненные в процессе обучения.
Учебный центр "Интерфейс" оказывает консалтинговые услуги по построению моделей бизнес-процессов, проектированию информационных систем, разработке структуры баз данных и т.д.
- Нужна помощь в поиске курса?
Наша цель заключается в обеспечении подготовки специалистов, когда и где им это необходимо. Возможна корректировка программ курсов по желанию заказчиков! Мы расскажем Вам о том, что интересует именно Вас, а не только о том, что жестко зафиксировано в программе курса. Если вам нужен курс, который вы не видите на графике или у нас на сайте, или если Вы хотите пройти курс в другое время и в другом месте, пожалуйста, сообщите нам, по адресу
Деревья являются одними из наиболее широко распространенных структур данных в информатике и программировании, которые представляют собой иерархические структуры в виде набора связанных узлов.
– это структура данных , представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов ( рис. 31.1). Каждый элемент дерева называется вершиной (узлом) дерева . Вершины дерева соединены направленными дугами, которые называют ветвями дерева . Начальный узел дерева называют корнем дерева , ему соответствует нулевой уровень. Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви.
Каждое дерево обладает следующими свойствами:
- существует узел, в который не входит ни одной дуги (корень);
- в каждую вершину, кроме корня, входит одна дуга.
Деревья особенно часто используют на практике при изображении различных иерархий. Например, популярны генеалогические деревья.
Рис.
31.1.
Все вершины, в которые входят ветви, исходящие из одной общей вершины, называются потомками , а сама вершина – предком . Для каждого предка может быть выделено несколько. Уровень потомка на единицу превосходит уровень его предка. Корень дерева не имеет предка, а листья дерева не имеют потомков.
Высота (глубина) дерева определяется количеством уровней, на которых располагаются его вершины. Высота пустого дерева равна нулю, высота дерева из одного корня – единице. На первом уровне дерева может быть только одна вершина – корень дерева , на втором – потомки корня дерева, на третьем – потомки потомков корня дерева и т.д.
Поддерево – часть древообразной структуры данных, которая может быть представлена в виде отдельного дерева.
Степенью вершины в дереве называется количество дуг, которое из нее выходит. Степень дерева равна максимальной степени вершины, входящей в дерево . При этом листьями в дереве являются вершины, имеющие степень нуль. По величине степени дерева различают два типа деревьев:
- двоичные – степень дерева не более двух;
- сильноветвящиеся – степень дерева произвольная.
Упорядоченное дерево – это дерево , у которого ветви, исходящие из каждой вершины, упорядочены по определенному критерию.
Деревья являются рекурсивными структурами, так как каждое поддерево также является деревом. Таким образом, дерево можно определить как рекурсивную структуру, в которой каждый элемент является:
- либо пустой структурой;
- либо элементом, с которым связано конечное число поддеревьев.
Действия с рекурсивными структурами удобнее всего описываются с помощью рекурсивных алгоритмов.
Списочное представление деревьев основано на элементах, соответствующих вершинам дерева. Каждый элемент имеет поле данных и два поля указателей: указатель на начало списка потомков вершины и указатель на следующий элемент в списке потомков текущего уровня. При таком способе представления дерева обязательно следует сохранять указатель на вершину, являющуюся корнем дерева .
Для того, чтобы выполнить определенную операцию над всеми вершинами дерева необходимо все его вершины просмотреть. Такая задача называется обходом дерева .
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая вершина встречается только один раз.
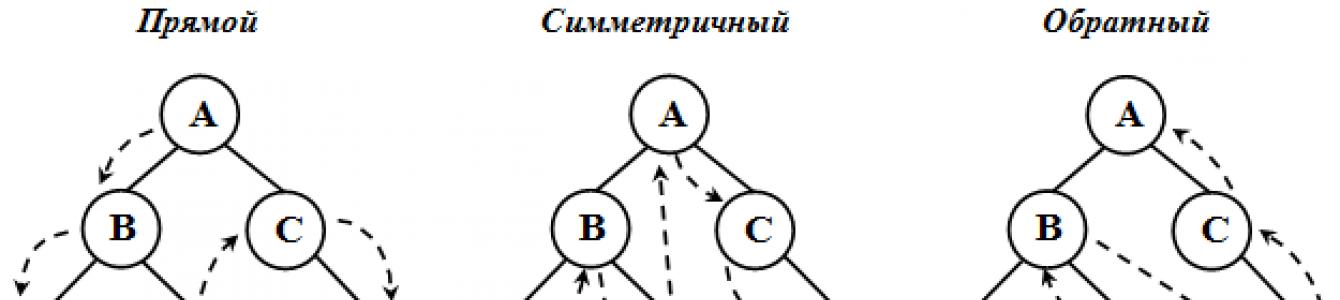
При обходе все вершины дерева должны посещаться в определенном порядке. Существует несколько способов обхода всех вершин дерева. Выделим три наиболее часто используемых способа обхода дерева ( рис. 31.2):
- прямой;
- симметричный;
- обратный.

Рис. 31.2.
Существует большое многообразие древовидных структур данных. Выделим самые распространенные из них: бинарные (двоичные) деревья, красно-черные деревья, В-деревья, АВЛ-деревья , матричные деревья, смешанные деревья и т.д.
Бинарные деревья
Бинарные деревья являются деревьями со степенью не более двух.
Бинарное (двоичное) дерево – это динамическая структура данных , представляющее собой дерево , в котором каждая вершина имеет не более двух потомков ( рис. 31.3). Таким образом, бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья. На каждый элемент дерева имеется ровно одна ссылка .

Рис. 31.3.
Каждая вершина бинарного дерева является структурой, состоящей из четырех видов полей. Содержимым этих полей будут соответственно:
- информационное поле (ключ вершины);
- служебное поле (их может быть несколько или ни одного);
- указатель на левое поддерево ;
- указатель на правое поддерево .
По степени вершин бинарные деревья делятся на ( рис. 31.4):

Рис. 31.4.
- строгие – вершины дерева имеют степень ноль (у листьев) или два (у узлов);
- нестрогие – вершины дерева имеют степень ноль (у листьев), один или два (у узлов).
Двоичные деревья поиска или бинарные деревья(binary tree) — это структура данных, состоящая из:
- одного единственного корневого узла, который не имеет родителей;
- остальных узлов, которые имеют одного единственного родителя и не более двух потомков.
Каждый узел дерева может быть корневым узлом для одного из своих поддеревьев(subtree) . Родительский узел — это узел, который имеет одного или двух потомков. Тот узел, который не имеет потомков, называется листом или листовым узлом . Двоичные деревья поиска названы так не просто потому что каждый узел дерева может иметь два потомка. Ключ левого потомка данного узла должен быть меньше, чем значение, которое хранит этот узел. Ключ правого потомка должен быть больше значения, которое хранится в родительском узле (см.рисунок).
В общем случае структуру для хранения узла можно представить следующим образом(на языке С):
typedef struct _Node int data ; struct Node * parent ; struct Node * left ; struct Node * right ; } Node ; |
Структура, представляющая узел хранит сами данные(поле data ) и три указателя — на родительский узел, левого и правого потомков. У корневого узла дерева поле parent будет равно NULL . Сохранение ссылки на родительский узел на самом деле необязательно. Но в некоторых случаях используется.
Еще раз взгляните на рисунок выше.
Корневой узел содержит в себе значение 27. Значение, которое хранит его левый потомок должно быть меньше, чем значение родительского узла. Мы видим там число 14 (14 < 27). Правый же потомок хранит больше значение(35 > 27) и так далее. Временная сложность процедуры поиска в двоичном дереве поиска оценивается как O(logN) . Допустим, что нам нужно найти вершину с ключом, равным 31.
Для того, чтобы найти этот узел, мы сначала сравниваем его со значением в корне. Корень хранит число 27, которое не является искомым элементом(21 != 27). При этом значение искомого элемента больше(31 > 27), чем значение, хранимое в текущем узле, а это значит, что поиск следует продолжить в правом поддереве. Теперь мы пришли в узел со значением 35. Это также не то, что мы искали, поэтому мы двигаемся дальше, а именно в левое поддерево(так как 31 < 35).
В итоге мы приходим в узел со значением 31, а это именно тот элемент, который мы искали. Возможно вся эта процедура уже вам напомнила обычный двоичный поиск в упорядоченном массиве. Это действительно так. Чем же тогда такое дерево лучше обычного массива? Помимо того же преимущества в скорости поиска, бинарное дерево упрощает процедуру вставки нового элемента в середину последовательности, так как в случае с бинарным деревом нам нужно лишь поменять несколько ссылок.
Но на самом деле у двоичного дерева есть один недостаток. И в некоторых ситуациях он может оказаться довольно существенным. Двоичное дерево поиска хорошо работает со случайными данными. В наихудшем случае, при поступлении на вход заведомо отсортированных данных, мы получаем вырожденную временную сложность O(N) . Так как в этом случае элементы будут всегда вставляться только в одно поддерево. В итоге мы получим обычный связный список и потеряем все преимущества двоичного поиска.
Как решить данную проблему? Для этого используются сбалансированные деревья, вроде красно-черных деревьев, которые предотвращают подобные ситуации в принципе. Но и сложность реализации повышается. Однако порой эта сложность полностью себя оправдывает.
Теперь приведем реализацию бинарного дерева с операциями вставки нового узла и поиска.
Реализация бинарного дерева на языке С.
Еще раз приведем реализацию структуры, представляющей узел дерева:
typedef struct _Node { int data; struct Node *parent; struct Node *left; struct Node *right; } Node;
typedef struct _Node int data ; struct Node * parent ; struct Node * left ; struct Node * right ; } Node ; |
Теперь структуру, описывающую само дерево поиска. В структуре будет храниться ссылка на корень дерева и количество узлов в нем.
typedef struct _BinaryTree { Node *root; int size; } BinaryTree;
typedef struct _BinaryTree Node * root ; int size ; } BinaryTree ; |
Напишем метод для создания нового дерева, который вернет указатель на созданное дерево.
BinaryTree *createTree() { BinaryTree *tree = (BinaryTree*)malloc(sizeof(BinaryTree)); tree->size = 0; tree->root = NULL; }
BinaryTree * createTree () BinaryTree * tree = (BinaryTree * ) malloc (sizeof (BinaryTree ) ) ; tree -> size = 0 ; tree -> root = NULL ; |
Добавление нового узла.
Теперь реализуем метод для добавления нового элемента в дерево. Если дерево еще пусто(root указывает на NULL ), то создаем корень дерева, если нет, то сравниваем значение, которое должен хранить новый элемент со значением текущего узла. Если оно меньше, то двигаемся в левое поддерево, а если больше — в правое, пока не найдем пустой узел, в который можно будет добавить данные:
//добавление нового узла Node *addNode(BinaryTree *tree, int data) { Node *newNode = (Node*)malloc(sizeof(Node)); newNode->data = data; newNode->left = NULL; newNode->right = NULL; if(tree->root == NULL) { tree->root = newNode; tree->size++; return newNode; }else { Node *currentNode = tree->root; Node *parent; while(true) { parent = currentNode; if(data < currentNode->data) { //идем в левое поддерево currentNode = currentNode->left; //нашли пустой узел? if(currentNode == NULL) { //добавляем сюда новый узел parent->left = newNode; tree->size++; return newNode; } }else { //идем в правое поддерево currentNode = currentNode->right; //нашли пустой узел? if(currentNode == NULL) { //добавляем сюда новый узел parent->right = newNode; tree->size++; return newNode; } } } } }
//добавление нового узла Node * addNode (BinaryTree * tree , int data ) Node * newNode = (Node * ) malloc (sizeof (Node ) ) ; newNode -> data = data ; newNode -> left = NULL ; newNode -> right = NULL ; if (tree -> root == NULL ) tree -> root = newNode ; tree -> size ++ ; return newNode ; } else Node * currentNode = tree -> root ; Node * parent ; while (true ) parent = currentNode ; if (data < currentNode -> data ) //идем в левое поддерево currentNode = currentNode -> left ; //нашли пустой узел? if (currentNode == NULL ) //добавляем сюда новый узел parent -> left = newNode ; tree -> size ++ ; return newNode ; } else //идем в правое поддерево currentNode = currentNode -> right ; //нашли пустой узел? if (currentNode == NULL ) //добавляем сюда новый узел parent -> right = newNode ; tree -> size ++ ; return newNode ; |
Данный метод возвращает указатель на добавленный узел дерева.
Теперь мы можем создать новое дерево и добавить туда несколько элементов.
BinaryTree *tree = createTree(); printf("%s = %i\n", "Count:", tree->size); addNode(tree, 50); addNode(tree, 10); addNode(tree, 75);
BinaryTree * tree = createTree () ; printf ("%s = %i\n" , "Count:" , tree -> size ) ; addNode (tree , 50 ) ; addNode (tree , 10 ) ; addNode (tree , 75 ) ; |
Поиск узла с заданным ключом.
Поиск узла в двоичном дереве подразумевает перемещение по дереву и сравнение искомого ключа с ключами, которые хранятся в каждом узле. При каждом сравнении возможны три различные ситуации:
1). Значение ключа совпадает со значением в просматриваемом узле. Значит, элемент найден и мы возвращаем указатель на него.
2). Значение ключа меньше, чем значение, которое хранится в текущем узле. Значит, нужно продолжить поиск в левом поддереве. currentNode = currentNode->left .
3). Значение ключа больше, чем значение, которое хранится в текущем узле. Значит, нужно продолжить поиск в правом поддереве. currentNode = currentNode -> right .
Теперь приведем реализацию самой функции поиска. Если элемент найден не будет, то функция вернет значение NULL .
//поиск узла Node *search(BinaryTree *tree, int key) { Node *currentNode = tree->root; while(currentNode->data != key) { if(key < currentNode->data) currentNode = currentNode->left; else currentNode = currentNode->right; if(currentNode == NULL) return NULL; } return currentNode; }
//поиск узла Node * search (BinaryTree * tree , int key ) Node * currentNode = tree -> root ; while (currentNode -> data != key ) if (key < currentNode -> data ) currentNode = currentNode -> left ; else currentNode = currentNode -> right ; if (currentNode == NULL ) return NULL ; return currentNode ; |
Обход дерева.
Процедурой обхода дерева называется посещение всех узлов дерева по одному разу в определенном порядке. Существует три разных порядка обхода: прямой , центрированный (симметричный) и обратный. Мы рассмотри здесь реализацию наиболее часто используемой процедуры обхода, а именно симметричного порядка обхода. Реализовав данный тип обхода вы с легкостью реализуете два оставшихся. Центрированный порядок обхода подразумевает посещение сначала двух потомков некоторого узла, а затем самого узла. В итоге он обрабатывает узлы дерева в порядке возрастания. Другие два типа обхода используются в разборе алгебраических выражений.
Так как деревья сами по себе обладают рекурсивной структурой, то и обход мы также выполним с применением рекурсии. Итак, наш алгоритм будет состоять из следующих шагов:
1). Обход левого поддерева.
2). Посещение узла(подразумевает какие-то операции над узлом, в нашем случае это просто вывод значения, хранимого в узле на экран).
3). Обход правого поддерева.
Данный алгоритм очень легко реализуется:
//симметричный обход дерева void inorder(BinaryTree *tree, Node *localRoot) { if(localRoot != NULL) { inorder(tree, localRoot->left); printf("%i -> ", localRoot->data); inorder(tree, localRoot->right); } }
//симметричный обход дерева void inorder (BinaryTree * tree , Node * localRoot ) |
Теги: Двоичное дерево поиска. БДП. Итреативные алгоритмы работы с двоичным деревом поиска.
Двоичное дерево поиска. Итеративная реализация.
Д воичные деревья – это структуры данных, состоящие из узлов, которые хранят значение, а также ссылку на свою левую и правую ветвь. Каждая ветвь, в свою очередь, является деревом. Узел, который находится в самой вершине дерева принято называть корнем (root), узлы, находящиеся в самом низу дерева и не имеющие потомков называют листьями (leaves). Ветви узла называют потомками (descendants). По отношению к своим потомкам узел является родителем (parent) или предком (ancestor). Также, развивая аналогию, имеются сестринские узлы (siblings – родные братья или сёстры) – узлы с общим родителем. Аналогично, у узла могут быть дяди (uncle nodes) и дедушки и бабушки (grandparent nodes). Такие названия помогают понимать различные алгоритмы.
Двоичное дерево. На этом рисунке узел 10 корень, 7 и 12 его наследники. 6, 9, 11, 14 - листья. 7 и 12, также как и 6 и 9 являются сестринскими узлами, 10 - это дедушка узла 6, а 12 - дядя узла 6 и узла 9
Двоичные деревья одна из самых простых структур (по сравнению, например, с другими деревьями). Они обычно реализуют самый базовый и самый естественный способ классификации элементов – делят их по определённому признаку, размещая одну группу в левом поддереве, а другую группу в правом. В поддеревьях рекурсивно поддерживается такой же порядок, за счёт чего узлы дерева упорядочиваются.
Такое размещение – слева меньше, справа больше – не обязательно, можно располагать элементы, которые меньше, справа. Отношение БОЛЬШЕ и МЕНЬШЕ – это не обязательно естественная сортировка по величине, это некоторая бинарная операция, которая позволяет разбить элементы на две группы.
Для реализации бинарного дерева поиска будем использовать структуру Node, которая содержит значение, ссылку на правое и левое поддерево, а также ссылку на родителя. Ссылка на родительский узел, в принципе, не является обязательной, однако сильно упрощает и ускоряет все алгоритмы. Далее, ради тренировки, мы ещё рассмотрим реализацию без ссылки на родителя.
ЗАМЕЧАНИЕ: мы рассматриваем случай, когда в дереве все значения разные и не равны NULL. Деревья с повторяющимися узлами рассмотрим позднее.
Обычно в качестве типа данных мы используем void* и далее передаём функции сравнения через указатели. В этот раз будем использовать пользовательский тип и макросы.
Typedef int T; #define CMP_EQ(a, b) ((a) == (b)) #define CMP_LT(a, b) ((a) < (b)) #define CMP_GT(a, b) ((a) > (b)) typedef struct Node { T data; struct Node *left; struct Node *right; struct Node *parent; } Node;
Сначала, как обычно, напишем функцию, которая создаёт новый узел. Она принимает в качестве аргументов значение и указатель на своего родителя. Корневой элемент не имеет родителя, значение указателя parent равно NULL.
Node* getFreeNode(T value, Node *parent) { Node* tmp = (Node*) malloc(sizeof(Node)); tmp->left = tmp->right = NULL; tmp->data = value; tmp->parent = parent; return tmp; }
Разберёмся со вставкой. Возможны следующие ситуации
- 1) Дерево пустое. В этом случае новый узел становится корнем ДДП.
- 2) Новое значение меньше корневого. В этом случае значение должно быть вставлено слева. Если слева уже стоит элемент, то повторяем эту же операцию, только в качестве корневого узла рассматриваем левый узел. Если слева нет элемента, то добавляем новый узел.
- 3) Новое значение больше корневого. В этом случае новое значение должно быть вставлено справа. Если справа уже стоит элемент, то повторяем операцию, только в качестве корневого рассматриваем правый узел. Если справа узла нет, то вставляем новый узел.
Пусть нам необходимо поместить в ДДП следующие значения
10 7 9 12 6 14 11 3 4
Первое значение становится корнем.
Дерево с одним узлом. Равных NULL потомков не рисуем
Второе значение меньше десяти, так что оно помещается слева.
Если значение меньше, то помещаем его слева
Число 9 меньше 10, так что узел должен располагаться слева, но слева уже стоит значение. 9 больше 7, так что новый узел становится правым потомком семи.
Двоичное дерево поиска после добавления узлов 10, 7, 9
Число 12 помещается справа от 10.
6 меньше 10 и меньше 7...
Добавляем оставшиеся узлы 14, 3, 4, 11
Функция, добавляющая узел в дерево
Два узла. Первый – вспомогательная переменная, чтобы уменьшить писанину, второй – тот узел, который будем вставлять.
Node *tmp = NULL; Node *ins = NULL;
Проверяем, если дерево пустое, то вставляем корень
If (*head == NULL) { *head = getFreeNode(value, NULL); return; }
Проходим по дереву и ищем место для вставки
Tmp = *head;
Пока не дошли до пустого узла
While (tmp) {
Если значение больше, чем значение текущего узла
If (CMP_GT(value, tmp->data)) {
Если при этом правый узел не пустой, то за корень теперь считаем правую ветвь и начинаем цикл сначала
If (tmp->right) { tmp = tmp->right; continue;
Если правой ветви нет, то вставляем узел справа
} else { tmp->right = getFreeNode(value, tmp); return; }
Также обрабатываем левую ветвь
} else if (CMP_LT(value, tmp->data)) { if (tmp->left) { tmp = tmp->left; continue; } else { tmp->left = getFreeNode(value, tmp); return; } } else { exit(2); } }
Void insert(Node **head, int value) { Node *tmp = NULL; Node *ins = NULL; if (*head == NULL) { *head = getFreeNode(value, NULL); return; } tmp = *head; while (tmp) { if (CMP_GT(value, tmp->data)) { if (tmp->right) { tmp = tmp->right; continue; } else { tmp->right = getFreeNode(value, tmp); return; } } else if (CMP_LT(value, tmp->data)) { if (tmp->left) { tmp = tmp->left; continue; } else { tmp->left = getFreeNode(value, tmp); return; } } else { exit(2); } } }
Рассмотрим результат вставки узлов в дерево. Очевидно, что структура дерева будет зависеть от порядка вставки элементов. Иными словами, форма дерева зависит от порядка вставки элементов.
Если элементы не упорядочены и их значения распределены равномерно, то дерево будет достаточно сбалансированным, то есть путь от вершины до всех листьев будет одинаковый. В таком случае максимальное время доступа до листа равно log(n), где n – это число узлов, то есть равно высоте дерева.
Но это только в самом благоприятном случае. Если же элементы упорядочены, то дерево не будет сбалансировано и растянется в одну сторону, как список; тогда время доступа до последнего узла будет порядка n. Это слабая сторона ДДП, из-за чего применение этой структуры ограничено.
Дерево, которое получили вставкой чередующихся возрастающей и убывающей последовательностей (слева) и полученное при вставке упорядоченной последовательности (справа)
Для решения этой проблемы можно производить балансировку дерева, или использовать структуры, которые автоматически проводят самобалансировку во время вставки и удаления.
Поиск в дереве
И звестно, что слева от узла располагается элемент, который меньше чем текущий узел. Из чего следует, что если у узла нет левого наследника, то он является минимумом в дереве. Таким образом, можно найти минимальный элемент дерева
Node* getMinNode(Node *root) { while (root->left) { root = root->left; } return root; }
Аналогично, можно найти максимальный элемент
Node* getMaxNode(Node *root) { while (root->right) { root = root->right; } return root; }
Опять же, если дерево хорошо сбалансировано, то поиск минимума и максимума будет иметь сложность порядка log(n), а в случае плохой балансировки стремится к n.
Поиск нужного узла по значению похож на алгоритм бинарного поиска в отсортированном массиве. Если значения больше узла, то продолжаем поиск в правом поддереве, если меньше, то продолжаем в левом. Если узлов уже нет, то элемент не содержится в дереве.
Node *getNodeByValue(Node *root, T value) { while (root) { if (CMP_GT(root->data, value)) { root = root->left; continue; } else if (CMP_LT(root->data, value)) { root = root->right; continue; } else { return root; } } return NULL; }
Удаление узла
С уществует три возможных ситуации.
- 1) У узла нет наследников (удаляем лист). Тогда он просто удаляется, а его родитель обнуляет указатель на него.
Удаляем лист
Просто исключаем его из дерева
- 2) У узла один наследник. В этом случае узел подменяется своим наследником.
- 3) У узла оба наследника. В этом случае узел не удаляем, а заменяем его значение на максимум левого поддерева. После этого удаляем максимум левого поддерева. (Напомню, что мы условились, что слева элементы меньше корневого).
У узла 7 два наследника. Находим максимум его левого поддерева (это 6)
Узел не удаляем, а копируем на его место значение максимума левого поддерева и удаляем этот узел
У узла 6 один наследник
Копируем на его место единственного наследника
Максимум левого поддерева имеет не более одного наследника, так что он удаляется просто. Известно, что все значения слева от корня меньше корня. Соответственно, максимум левого поддерева будет, с одной стороны, больше всех элементов левого поддерева, с другой стороны меньше всех значений правого поддерева.
Наша функция будет принимать в качестве аргумента узел, который необходимо удалить.
If (target->left && target->right) { //Оба наследника есть } else if (target->left) { //Есть только левый наследник } else if (target->right) { //Есть только правый наследник } else { //Нет наследников } free(target);
Если нет наследников, то нужно узнать, каким поддеревом относительно родителя является узел
If (target == target->parent->left) { target->parent->left = NULL; } else { target->parent->right = NULL; }
Если есть только правый или только левый наследник, подменяем наследником удаляемый узел. Перед этим нужно узнать, правым или левым наследником является удаляемый узел.
If (target == target->parent->left) { target->parent->left = target->left; } else { target->parent->right = target->left; }
If (target == target->parent->right) { target->parent->right = target->right; } else { target->parent->left = target->right; }
Если оба наследника, то сначала находим максимум левого поддерева
Node *localMax = findMaxNode(target->left);
Затем подменяем значение удаляемого узла на него
Target->data = localMax->data;
После чего удаляем этот узел
RemoveNodeByPtr(localMax);
return;
Здесь мы использовали рекурсию, хотя я обещал этого не делать. Вызов будет всего один, так как известно, что максимум не содержит обоих наследников и является правым наследником
своего родителя. Если хотите заменить вызов функции, то придётся скопировать оставшийся код.
Void removeNodeByPtr(Node *target) { if (target->left && target->right) { Node *localMax = findMaxNode(target->left); target->data = localMax->data; removeNodeByPtr(localMax); return; } else if (target->left) { if (target == target->parent->left) { target->parent->left = target->left; } else { target->parent->right = target->left; } } else if (target->right) { if (target == target->parent->right) { target->parent->right = target->right; } else { target->parent->left = target->right; } } else { if (target == target->parent->left) { target->parent->left = NULL; } else { target->parent->right = NULL; } } free(target); }
Упростим работу и сделаем обёртку вокруг функции, чтобы она удаляла узел по значению
Void deleteValue(Node *root, T value) { Node *target = getNodeByValue(root, value); removeNodeByPtr(target); }
Для проверки можно ввести функцию печати дерева. Так как мы ещё не научились обходить деревья, вывод осавляет желать лучшего.
Void printTree(Node *root, const char *dir, int level) { if (root) { printf("lvl %d %s = %d\n", level, dir, root->data); printTree(root->left, "left", level+1); printTree(root->right, "right", level+1); } }
Проверка
Void main() { Node *root = NULL; insert(&root, 10); insert(&root, 12); insert(&root, 8); insert(&root, 9); insert(&root, 7); insert(&root, 3); insert(&root, 4); printTree(root, "root", 0); printf("max = %d\n", findMaxNode(root)->data); printf("min = %d\n", findMinNode(root)->data); deleteValue(root, 4); printf("parent of 7 is %d\n", getNodeByValue(root, 7)->parent->data); printTree(root, "root", 0); deleteValue(root, 8); printTree(root, "root", 0); printf("------------------\n"); deleteValue(root, 10); printTree(root, "root", 0); getch(); }






