
Информацию, оформленную в виде таблиц, гораздо удобнее анализировать и использовать в различных расчетах, но когда необходимо сравнить данные нескольких похожих таблиц, визуально все это сделать очень сложно. Подходящее программное обеспечение всегда может выручить в подобной ситуации, и далее мы рассмотрим, как сравнить две таблицы в Excel, используя для этого разные методы анализа.
Сравнить таблицы в Excel нажатием одной кнопки к сожалению, не получится, и мало того, возможно для сравнения придется еще и некоторым образом подготовить данные, а также написать формулу.
В зависимости от необходимого результата подбирается и способ сравнения данных из таблиц. Самый простой способ, это сравнение двух на первый взгляд одинаковых столбцов для выявления строк, в которых это отличие все же есть. Сравнивать таким образом можно как числовые значения, так и текст.
Сравним два столбца цифровых значений, в которых отличие имеется только в нескольких ячейках. Записав простую формулу в соседнем столбце, условие равенства двух ячеек «=B3=C3» , мы получим результат «ИСТИНА» , если содержимое ячеек одинаковое, и «ЛОЖ» , если содержимое ячеек отличается. Растянув формулу по всей высоте столбца сравниваемых значений очень легко будет найти отличающуюся ячейку.
Если нужно просто удостоверится в наличии или отсутствии отличий в столбцах, можно воспользоваться пунктом меню «Найти и выделить» , на вкладке «Главная» . Для этого нужно предварительно выделить сравниваемые столбцы, после чего выбирать уже необходимый пункт меню. В выпадающем списке необходимо выбрать «Выделить группу ячеек…» , а в появившемся окошке выбрать «отличия по строкам» .

Условное форматирование отличий в упорядоченных значениях
При желании можно применить к отличающимся ячейкам условное форматирование, делая заливку ячейки, меняя цвет текста и т.д. В этом случае нужно выбирать пункт «Условное форматирование»
, в выпадающем списке которого выбираем «Управление правилами»
.

В диспетчере правил выбираем пункт «Создать правило» , а в создании правил выбираем . Теперь мы можем задать формулу «=$B3<>$C3» для определения форматируемой ячейки, и задать для нее формат, нажав на кнопку «Формат» .



Теперь у нас имеется правило отбора ячеек, задано форматирование, и определен диапазон сравниваемый ячеек. После нажатия на кнопку «OK» , заданное нами правило будет применено.


Сравнение и форматирование отличий в неупорядоченных значениях
Сравнение таблиц Эксель не ограничивается сравнением упорядоченных значений. Иногда приходится сравнивать диапазоны перемешанных значений, в которых необходимо определить вхождение одного значения в диапазон других значений.
Например, у нас имеется набор значений, оформленный в виде двух столбцов, и еще один такой же набор значений. В первом наборе у нас имеются все значения от 1 до 20, а во втором некоторые значения отсутствуют и продублированы другими значениями. Наша задача выделить условным форматированием в первом наборе значения, которых нет во втором наборе.
Порядок действий следующий, выделяем первый набор данных, именуемый у нас «Столбец 1» , и в меню «Условное форматирование» выбираем пункт «Создать правило…» . В появившемся окошке выбираем , вписываем необходимую формулу «=СЧЁТЕСЛИ($C$3:$D$12;A3)=0» и выбираем способ форматирования.


В нашей формуле используется функция «СЧЁТЕСЛИ» , которая подсчитывает количество повторений значения из определенной ячейки «A3» в заданном диапазоне «$C$3:$D$12» , которым выступает наш второй столбец. В качестве сравниваемой ячейки необходимо указывать первую ячейку из диапазона значений, к которым будет применяться форматирование.
После применения созданного правила все ячейки с неповторяющимися значениями в другом наборе значений будут выделены указанным цветом.

Конечно же, есть и более сложные варианты сравнения двух таблиц в Excel, как например, сравнение цент товаров в новом и старом прайсах. Допустим, имеется две таблицы с ценами, и рядом с ценами в новой таблице нужно указать и старые цены для каждого товара, причем порядок товаров в списках не соблюдается.
Рядом с ценами в новой таблице в ячейке следующего столбца необходимо записать формулу, которая и будет производить выборку значений. В формуле мы будем применять функция «ВПР» , которая может вернуть значение из любого столбца в строке, в которой выполнилось условие поиска. Чтобы функция работала правильно, необходимо чтобы в столбце в каждой строке находились уникальные значения, по которым будет производится поиск. Если значения будут повторяться, учитываться будет только первое найденное.
Необходимая нам формула будет выглядеть следующим образом: «=ВПР(B18;$B$3:$C$10;2;ЛОЖЬ)» . Первое значение «B18» соответствует первой ячейке искомого наименования товара. Второе значение «$B$3:$C$10» означает постоянный адрес диапазона таблицы старого прайса, значения из которой нам понадобятся. Третье значение «2» означает номер столбца из выделенного диапазона, в ячейке которого мы и будем брать старую цену товара. И последнее значение «ЛОЖЬ» задает поиск только по точному совпадению значений. После протаскивания формулы по всему столбцу новой таблицы мы получим в этом столбце старые значения цен по каждой позиции, имеющейся в новой таблице. Напротив наименования последнего товара формула выводит сообщение ошибки «#Н/Д» , что свидетельствует об отсутствии данного наименования в старом прайсе.

Вариантов сравнения таблиц в Экселе может быть бесчисленное множество, причем некоторые из них можно провести только при помощи надстройки VBA.
Пусть имеется две таблицы значений, имеющих одинаковый состав и типы колонок. Требуется сравнить эти таблицы с целью определения различий, имеющихся между ними.
Домысливая условия задачи самыми распространенными обстоятельствами, дополнительно установим, что:
- Разный порядок одних и тех же строк в двух таблицах не делает таблицы различными (в задачах, где порядок строк существенен, всегда можно добавить колонку с номером строки, чтобы заметить их перестановку);
- В одной таблице не может быть двух одинаковых строк (а если такое есть, то всегда можно произвести свертку по всем колонкам с подсчетом одинаковых строк в добавленной колонке - это упростит интерпретацию результатов сравнения).
- Таблицы сравниваются путем непосредственного сравнения значений их элементов или ссылок. Если элементы таблиц содержат коллекции, то сравниваются только ссылки на коллекции без попыток определить равенство их содержания.
Второе уточнение автоматически приводит к тому, что в таблице всегда будут одна или более колонок, значение (комбинация значений) в которых будут уникальными и могут служить идентификатором строки. Такую колонку (набор колонок) можно называть ключом: простым в случае одной колонки или составным в более сложном случае. А еще лучше, по аналогии с регистрами, упомянутые колонки называть измерениями таблицы, а оставшиеся - ресурсами.
Выделение колонок-измерений позволяет при сравнении таблиц установить не только факт удаления или добавления строки, но и факт изменения строки, если в том же наборе измерений изменились ресурсы.
Например, при сравнении таблиц значений, полученных по оборотно-сальдовой ведомости счета учета сырья и материалов, измерениями будут колонки, содержащие номенклатуру и склад, а ресурсами - остатки и обороты счета. А при сравнении табличных частей «Товары» измерениями будут номенклатура, характеристика и серия, а ресурсами - все остальные реквизиты этой табличной части. И тогда путем сравнения версий табличных частей можно будет сказать, что такая-то номенклатура была удалена или добавлена, а такая-то - изменена.
При постановке задачи также определим форму представления результатов сравнения. Это наиболее уязвимое для критики решение. Поскольку от него зависит результат соревнования методов. Одна форма может быть удобной для одного метода, вторая для другого, третья для третьего, а практика в силу разнообразия задач и ситуаций ответу не помогает.
После долгих колебаний было принято следующее решение: результатом сравнения двух таблиц Таблица0 и Таблица1 должна быть таблица «Разница» той же структуры, что и сравниваемые таблицы. «Разница» должна содержать отличающиеся строки двух таблиц (удаленные, добавленные, измененные). При этом в дополнительном столбце «Знак» должна стоять отметка: 0 - если строка имеется в Таблице0 и 1 - если строка имеется в Таблице1. Это можно интерпретировать как 0 - строка удалена, 1 - добавлена, или 0 - строка до изменения, 1 - после. Кроме того (внимание!), строки с одинаковыми значениями измерений должны быть расположены друг под другом, что реализует удобный для визуального контроля способ «связывания» строк до и после изменения.
Например, если сравнить предлагаемым способом таблицу "7 класс" с таблицей "8 класс", то должна получиться таблица "Разница".
| 7 класс | 8 класс | Разница | ||||||
| Предмет | Оценка | Предмет | Оценка | Предмет | Оценка | Знак | ||
| Пение | 5 | Литература | 5 | Пение | 5 | 0 | ||
| Литература | 5 | Алгебра | 4 | Алгебра | 5 | 0 | ||
| Алгебра | 5 | Физика | 5 | Алгебра | 4 | 1 | ||
| Физика | 5 | Химия | 4 | Химия | 4 | 1 |
Ну и последнее. Не так часто, но все же встречаются случаи, когда сравнению подвергаются уже упорядоченные по ключевым полям таблицы. Добавим это условие к задаче, чтобы расширить набор тестируемых алгоритмов методом, который специально заточен под этот случай.
2.Критерии оценки и методика испытаний
Главным критерием оценки естественно выбрать время выполнения сравнения. Дополнительным критерием может служить простота функции сравнения. Время выполнения сравнения можно замерить специально созданной для этого обработкой. Простоту функций предлагается оценивать субъективно.
Обработка, с озданная для испытаний, генерирует таблицу значений с заданным числом строк и столбцов и заданным количеством измерений. Тип данных элементов выбирается из ограниченного списка примитивных типов: строка, число и дата, также можно задать длину значения. Значения элементов таблицы формируются случайным образом. Путем изменения первой таблицы формируется вторая. Количество изменений задается в процентном отношении к числу строк первой таблицы тремя различными показателями: процент удалений, изменений и добавлений. Также задается число повторений для определения среднего времени работы метода. Все тестируемые методы запускаются один за другим на одних и тех же тестовых таблицах. Используемая при тестировании обработка прикреплена к данной публикации, чтобы результаты можно было перепроверить на другом оборудовании и в другом программном окружении.
3.Краткое описание сравниваемых методов
Всего для детального тестирования было отобрано семь различных методов:
3.1. Свертка и сортировка
Суть метода заключается в объединении таблиц путем дописывания в цикле по одной строке из первой таблицы ко второй. Затем делается добавление дополнительного столбца "Счёт" для последующего подсчета одинаковых строк. Подсчет делается сверткой по всем столбцам. Так определяются одинаковые и разные строки в первой и второй таблице. Те строки, которые встретились в объединенной таблице по одной, переписываются в таблицу разниц, которая затем сортируется по измерениям, чтобы строки до и после изменений оказались рядом. Вот код данной функции
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт ВсеКолонки = ""; Для Каждого Колонка Из Таблица0.Колонки Цикл ВсеКолонки = ВсеКолонки + ", " + Колонка.Имя КонецЦикла; ВсеКолонки = Сред(ВсеКолонки, 2); Таблица = Таблица1.Скопировать(); Таблица.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число")); Таблица.ЗаполнитьЗначения(1, "Знак"); Для Каждого Строка Из Таблица0 Цикл ЗаполнитьЗначенияСвойств(Таблица.Добавить(), Строка) КонецЦикла; Таблица.Колонки.Добавить("Счёт"); Таблица.ЗаполнитьЗначения(1, "Счёт"); Таблица.Свернуть(ВсеКолонки, "Знак, Счёт"); Ответ = Таблица.Скопировать(Новый Структура("Счёт", 1), ВсеКолонки + ", Знак"); Ответ.Сортировать(Измерения); Возврат Ответ КонецФункции
3.2 Трюк, свертка и сортировка
Данная функция является небольшой модификацией предыдущей функции за счет того, что дописывание первой таблицы ко второй идет не по строкам, а по столбцам. Это в определенном диапазоне условий ускоряет операцию объединения таблиц
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт ВсеКолонки = ""; Для Каждого Колонка Из Таблица0.Колонки Цикл ВсеКолонки = ВсеКолонки + ", " + Колонка.Имя КонецЦикла; ВсеКолонки = Сред(ВсеКолонки, 2); Таблица = Таблица1.Скопировать(); Таблица.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число")); Таблица.ЗаполнитьЗначения(1, "Знак"); Для ё = 1 По Таблица0.Количество() Цикл Таблица.Вставить(0) КонецЦикла; Для ё = 0 По Таблица0.Колонки.Количество() - 1 Цикл Таблица.ЗагрузитьКолонку(Таблица0.ВыгрузитьКолонку(ё), ё) КонецЦикла; Таблица.Колонки.Добавить("Счёт"); Таблица.ЗаполнитьЗначения(1, "Счёт"); Таблица.Свернуть(ВсеКолонки, "Знак, Счёт"); Ответ = Таблица.Скопировать(Новый Структура("Счёт", 1), ВсеКолонки + ", Знак"); Ответ.Сортировать(Измерения); Возврат Ответ КонецФункции
3.3. Соединение по индексу
Данная функция построена на простой и ясной идее. В цикле перебираются строки первой таблицы. Для каждой строки делается попытка найти строку во второй таблице, соответствующую ей по значению измерений, с помощью метода "НайтиСтроки". Ресурсы найденных строк затем сравниваются на предмет наличия расхождений, найденная строка во второй таблице помечается нулем, чтобы затем отобрать непомеченные "единичные" строки как отсутствующие в первой таблице. Чтобы метод НайтиСтроки работал быстро, для второй таблицы создается один индекс по всей совокупности измерений.
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт Отбор = Новый Структура(Измерения); Ресурсы = Новый Массив; Для ИндексКолонки = 0 По Таблица0.Колонки.Количество() - 1 Цикл Если НЕ Отбор.Свойство(Таблица0.Колонки[ИндексКолонки].Имя) Тогда Ресурсы.Добавить(ИндексКолонки) КонецЕсли КонецЦикла; Таблица1.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число")); Таблица1.ЗаполнитьЗначения(1, "Знак"); НовыйИндекс = Таблица1.Индексы.Добавить(Измерения); Разница = Таблица1.СкопироватьКолонки(); Для Каждого Строка0 Из Таблица0 Цикл ЗаполнитьЗначенияСвойств(Отбор, Строка0); Строки1 = Таблица1.НайтиСтроки(Отбор); Если Строки1.Количество() = 0 Тогда ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0) Иначе Строка1 = Строки1; Для Каждого Ресурс Из Ресурсы Цикл Если Строка0[Ресурс] <> Строка1[Ресурс] Тогда ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0); ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1); Прервать КонецЕсли КонецЦикла; Строка1.Знак = 0 КонецЕсли КонецЦикла; Для Каждого Строка1 Из Таблица1.НайтиСтроки(Новый Структура("Знак", 1)) Цикл ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1); КонецЦикла; Таблица1.Колонки.Удалить("Знак"); Таблица1.Индексы.Удалить(НовыйИндекс); Возврат Разница КонецФункции
3.4. Соединение по соответствию
Данная функция алгоритмически повторяет предыдущую, за исключением того, что вместо обычного индекса используется "самодельный" индекс на основе соответствия. Для этого вторая таблица предварительно обходится, в результате чего ссылки на ее строки запоминаются в дереве поиска, построенном на основе соответствия
Функция РазницаТаблицЗначений_(Таблица0, Таблица1, СтрокаИзмерений) Экспорт Таблица1.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число")); Таблица1.ЗаполнитьЗначения(1, "Знак"); СтруктураИзмерений = Новый Структура(СтрокаИзмерений); Измерения = Новый Массив; Ресурсы = Новый Массив; Для Индекс = 0 По Таблица0.Колонки.Количество() - 1 Цикл ИмяКолонки = Таблица0.Колонки[Индекс].Имя; Если СтруктураИзмерений.Свойство(ИмяКолонки) Тогда Измерения.Добавить(Индекс) Иначе Ресурсы.Добавить(Индекс) КонецЕсли КонецЦикла; ИзмерениеПлюс = Измерения[Измерения.Количество() - 1]; Измерения.Удалить(Измерения.Количество() - 1); ХэшМап = Новый Соответствие; Для Каждого Строка1 Из Таблица1 Цикл Корень = ХэшМап; Для Каждого Измерение Из Измерения Цикл ЧастьКлюча = Строка1[Измерение]; Ветка = Корень[ЧастьКлюча]; Если Ветка = Неопределено Тогда Ветка = Новый Соответствие; Корень[ЧастьКлюча] = Ветка КонецЕсли; Корень = Ветка КонецЦикла; ЧастьКлюча = Строка1[ИзмерениеПлюс]; Корень[ЧастьКлюча] = Строка1 КонецЦикла; Измерения.Добавить(ИзмерениеПлюс); Разница = Таблица1.СкопироватьКолонки(); Для Каждого Строка0 Из Таблица0 Цикл Корень = ХэшМап; Для Каждого Измерение Из Измерения Цикл ЧастьКлюча = Строка0[Измерение]; Ветка = Корень[ЧастьКлюча]; Если Ветка = Неопределено Тогда ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0); Прервать КонецЕсли; Корень = Ветка КонецЦикла; Если Ветка <> Неопределено Тогда Для Каждого Ресурс Из Ресурсы Цикл Если Строка0[Ресурс] <> Ветка[Ресурс] Тогда ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка0); ЗаполнитьЗначенияСвойств(Разница.Добавить(), Ветка); Прервать КонецЕсли КонецЦикла; Ветка.Знак = 0 КонецЕсли КонецЦикла; Для Каждого Строка1 Из Таблица1.НайтиСтроки(Новый Структура("Знак", 1)) Цикл ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1); КонецЦикла; Таблица1.Колонки.Удалить("Знак"); Возврат Разница КонецФункции
3.5. Слияние
Эта функция предполагает отсортированность сравниваемых таблиц по ключевым измерениям. В ходе ее работы строки двух таблиц читаются по очереди, сравниваясь между собой так, чтобы в итоге на выходе получалась слитая упорядоченная таблица без одинаковых строк.
Функция РазницаТаблицЗначений_(Таблица0, Таблица1, СтрокаИзмерений) Экспорт Таблица1.Колонки.Добавить("Знак", Новый ОписаниеТипов("Число")); Таблица1.ЗаполнитьЗначения(1, "Знак"); Разница = Таблица1.СкопироватьКолонки(); СтруктураИзмерений = Новый Структура(СтрокаИзмерений); Измерения = Новый Массив; Ресурсы = Новый Массив; Для Индекс = 0 По Таблица0.Колонки.Количество() - 1 Цикл ИмяКолонки = Таблица0.Колонки[Индекс].Имя; Если СтруктураИзмерений.Свойство(ИмяКолонки) Тогда Измерения.Добавить(Индекс) Иначе Ресурсы.Добавить(Индекс) КонецЕсли КонецЦикла; Сравнение = Новый СравнениеЗначений; Индекс1 = Таблица0.Количество() - 1; Индекс2 = Таблица1.Количество() - 1; Строка1 = Таблица0[Индекс1]; Строка2 = Таблица1[Индекс2]; Пока Истина Цикл Для Каждого Измерение Из Измерения Цикл РезультатСравнения = Сравнение.Сравнить(Строка1[Измерение], Строка2[Измерение]); Если РезультатСравнения <> 0 Тогда Прервать КонецЕсли КонецЦикла; Если РезультатСравнения = 0 Тогда Для Каждого Ресурс Из Ресурсы Цикл Если Строка1[Ресурс] <> Строка2[Ресурс] Тогда ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1); ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2); Прервать КонецЕсли КонецЦикла; Индекс1 = Индекс1 - 1; Индекс2 = Индекс2 - 1; Если Мин(Индекс1, Индекс2) < 0 Тогда Прервать КонецЕсли; Строка1 = Таблица0[Индекс1]; Строка2 = Таблица1[Индекс2]; ИначеЕсли РезультатСравнения > 0 Тогда ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1); Индекс1 = Индекс1 - 1; Если Индекс1 < 0 Тогда Прервать КонецЕсли; Строка1 = Таблица0[Индекс1] Иначе ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2); Индекс2 = Индекс2 - 1; Если Индекс2 < 0 Тогда Прервать КонецЕсли; Строка2 = Таблица1[Индекс2] КонецЕсли КонецЦикла; Пока Индекс1 >= 0 Цикл Строка1 = Таблица0[Индекс1]; ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка1); Индекс1 = Индекс1 - 1 КонецЦикла; Пока Индекс2 >= 0 Цикл Строка2 = Таблица1[Индекс2]; ЗаполнитьЗначенияСвойств(Разница.Добавить(), Строка2); Индекс2 = Индекс2 - 1 КонецЦикла; Таблица1.Колонки.Удалить("Знак"); Возврат Разница КонецФункции
3.6. Запрос - полное соединение
Функция основана на передаче в запрос двух таблиц, где они соединяются по равенству значений в измерениях. Небольшое усложнение связано с последующей "разверткой" в две строки строк, отличающихся по ресурсам.
Функция СтрЧасти(Строка, Разделитель) Экспорт ПозицияРазделителя = Найти(Строка, Разделитель); Если ПозицияРазделителя = 0 Тогда Ответ = Новый Массив; Ответ.Добавить(Строка); Иначе Ответ = СтрЧасти(Сред(Строка, ПозицияРазделителя + СтрДлина(Разделитель)), Разделитель); Ответ.Вставить(0, Сред(Строка, 1, ПозицияРазделителя - 1)) КонецЕсли; Возврат Ответ КонецФункции Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт Запрос = Новый Запрос("ВЫБРАТЬ | 0 КАК Знак{}, Т.Поле{} |ПОМЕСТИТЬ Т0 |ИЗ | &Таблица0 КАК Т |; | |//////////////////////////////////////////////////////////////////////////////// |ВЫБРАТЬ | 1 КАК Знак{}, Т.Поле{} |ПОМЕСТИТЬ Т1 |ИЗ | &Таблица1 КАК Т |; | |//////////////////////////////////////////////////////////////////////////////// |ВЫБРАТЬ | 0 КАК Знак |ПОМЕСТИТЬ Знаки | |ОБЪЕДИНИТЬ | |ВЫБРАТЬ | 1 |; | |//////////////////////////////////////////////////////////////////////////////// |ВЫБРАТЬ{} | ВЫБОР Знаки.Знак | КОГДА 0 | ТОГДА Т0.Поле | ИНАЧЕ Т1.Поле | КОНЕЦ КАК Поле,{} | Знаки.Знак |ИЗ | Т0 КАК Т0 | ПОЛНОЕ СОЕДИНЕНИЕ Т1 КАК Т1 | ПО (ИСТИНА) | {} И Т0.Поле = Т1.Поле{}, | Знаки КАК Знаки |ГДЕ | ({}Т0.Поле ЕСТЬ NULL И Знаки.Знак = 1 | ИЛИ Т1.Поле ЕСТЬ NULL И Знаки.Знак = 0 | {} ИЛИ Т0.Поле <> Т1.Поле{}) | |УПОРЯДОЧИТЬ ПО | {}Поле"); СтруктураИзмерений = Новый Структура(Измерения); Секции = СтрЧасти(Запрос.Текст, "{}"); Запрос.Текст = Секции; Для Каждого Колонка Из Таблица1.Колонки Цикл Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Колонка.Имя) КонецЦикла; Запрос.Текст = Запрос.Текст + Секции; Для Каждого Колонка Из Таблица1.Колонки Цикл Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Колонка.Имя) КонецЦикла; Запрос.Текст = Запрос.Текст + Секции; Для Каждого Колонка Из Таблица1.Колонки Цикл Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Колонка.Имя) КонецЦикла; Запрос.Текст = Запрос.Текст + Секции; Для Каждого Элемент Из СтруктураИзмерений Цикл Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Элемент.Ключ) КонецЦикла; Запрос.Текст = Запрос.Текст + Секции; Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Таблица1.Колонки.Имя); Для Каждого Колонка Из Таблица1.Колонки Цикл Если НЕ СтруктураИзмерений.Свойство(Колонка.Имя) Тогда Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Колонка.Имя) КонецЕсли КонецЦикла; Запрос.Текст = Запрос.Текст + Секции; Запрос.Текст = Запрос.Текст + СтрЗаменить(Секции, "Поле", Измерения); Запрос.УстановитьПараметр("Таблица0", Таблица0); Запрос.УстановитьПараметр("Таблица1", Таблица1); Возврат Запрос.Выполнить().Выгрузить() КонецФункции
3.7. Запрос - группировка
Эта функция построена ровно на той же идее, что и функция 3.1, только реализована внутри запроса
Функция РазницаТаблицЗначений(Таблица0, Таблица1, Измерения) Экспорт Запрос = Новый Запрос("ВЫБРАТЬ | 0 КАК Знак, | Т.Поле |ПОМЕСТИТЬ Т0 |ИЗ | &Таблица0 КАК Т |; | |//////////////////////////////////////////////////////////////////////////////// |ВЫБРАТЬ | 1 КАК Знак, | Т.Поле |ПОМЕСТИТЬ Т1 |ИЗ | &Таблица1 КАК Т |; | |//////////////////////////////////////////////////////////////////////////////// |ВЫБРАТЬ | Т.Знак, | Т.Поле |ПОМЕСТИТЬ Т |ИЗ | Т0 КАК Т | |ОБЪЕДИНИТЬ ВСЕ | |ВЫБРАТЬ | Т.Знак, | Т.Поле |ИЗ | Т1 КАК Т |; | |//////////////////////////////////////////////////////////////////////////////// |ВЫБРАТЬ | СУММА(Т.Знак) КАК Знак, | Т.Поле |ИЗ | Т КАК Т | |СГРУППИРОВАТЬ ПО | Т.Поле | |ИМЕЮЩИЕ | КОЛИЧЕСТВО(*) = 1 | |УПОРЯДОЧИТЬ ПО | Поле//"); ВсеКолонки = ""; Для Каждого Колонка Из Таблица1.Колонки Цикл ВсеКолонки = ВсеКолонки + ", Т." + Колонка.Имя КонецЦикла; Запрос.Текст = СтрЗаменить(Запрос.Текст, "Т.Поле", Сред(ВсеКолонки, 2)); Запрос.Текст = СтрЗаменить(Запрос.Текст, "Поле//", Измерения); Запрос.УстановитьПараметр("Таблица0", Таблица0); Запрос.УстановитьПараметр("Таблица1", Таблица1); Возврат Запрос.Выполнить().Выгрузить() КонецФункции
Все приведенные здесь функции были достаточно тщательно оттюнингованы для достижения максимального быстродействия. С учетом опыта, полученного в ходе совместного тюнинга на форуме функций для одномерного случая. Однако это было сделано не так тщательно как там, поэтому, возможно, из некоторых функций можно выжать еще немного быстродействия.
4. Результаты тестирования
4.1 Влияние числа строк
Исследуем зависимость времени сравнения от числа строк в таблицах. Для этого используем следующие значения параметров тестирования. Число строк - 20000, 40000, 60000, 80000, 100000, число колонок - 10, число ключевых колонок - 1, тип данных - строка, длина строки - 10, процент удалений, изменений, добавлений - 5, число повторов теста - 2. Получим следующую зависимость, которую удобнее представить в виде графика.
Эта зависимость для большинства методов практически линейна! Так и должно быть. Время работы метода НайтиСтроки при наличии индекса не зависит от числа строк, поэтому соединение по индексу выполняется за линейное время. То же самое при использовании соответствия и слияния. При полном соединении в запросе для соединения таблиц равного размера скорее всего используется хэш-матч.
Нелинейность времени сортировки относительно небольшого количества отличающихся строк чуть-чуть отклоняет от прямой зависимость для свертки. Хуже дела у метода с использованием объединения копированием колонок - именно этот способ копирования вносит существенную нелинейность вдобавок к небольшой нелинейности сортировки. Из-за этого выгода применения "трюка" объединения таблиц на числе строк более 60000 теряется.
4.2 Влияние длины значений
Теперь исследуем зависимость времени от длины значений типа строка. Число строк положим равным 50000. Остальные параметры такие же, как в 4.1. Результат представим в виде столбиковой диаграммы. Она лучше показывает соотношение времени работы разных методов и позволяет выделить лидера, которым в большинстве случаев яыляется метод свертки.

Видно, что зависимость времени от метода при изменении длины строки практически не меняется. Растет только время выполнения запросов.
Чтобы повысить информативность этой диаграммы в отношении запросных методов, здесь выделено в отдельные измерения время ввода таблиц в запрос. Для этого создана функция-пустышка, выполняющая только ввод таблиц в запрос и не выполняющая больше никакой другой работы. Большое время на ввод таблиц показывает, что запросной технике очень трудно конкурировать с методами-лидерами. Во многих случаях лидеры уже закончили работу к тому времени, когда исходные данные только оказались в запросе.
4.3 Влияние типов данных
Следующий интересный вопрос - отношение методов к типам данных. Его показывает следующая диаграмма. Здесь также число строк 50000, длина строкового и числового значения - 10. Остальное как в 4.1.

Из нее видно, что типданных сильнее всего сказывается на времени запросных методов. Для чисел лучше подходит группировка. И очень хорошо запросами обрабатываются даты.
4.3 Влияние числа колонок
Еще одна зависимость - это зависимость времени сравнения от числа колонок. Ее показывает следующая диаграмма. Число строк здесь 50000, тип данных - строка длины 10, процент добавлений, искажений и удалений по 5. Одна ключевая колонка.

Видно, что число колонок не сильно меняет сравнительную скорость методов. В наибольшей степени увеличение числа колонок замедляет работу запросов.
4.4 Влияние числа измерений
Более интересна зависимость от числа ключевых колонок, приведенная ниже. Число строк здесь 50000, тип данных - строка длины 10, процент добавлений, искажений и удалений по 5. Всего колонок 10.

Видно, что метод на основе соответствия, ранее показывавший неплохие результаты, теперь оказывается в аутсайдерах. Также ухудшается слияние. А вот поиск по индексу улучшается - за счет того, что сравнивать остается меньшее число колонок.
4.5 Влияние разницы размеров таблиц
Теперь обратим внимание на несимметричность методов 1 - 4 (свертки и соединения) относительно размеров сравниваемых таблиц. Всем этим методам выгоднее, чтобы первая таблица была меньше! Это подтверждает следующая таблица, которая показывает время сравнения двух таблиц 50000 и 40000 строк в разном порядке.

На приведенной диаграмме заметен любопытный артефакт. При данном количестве строк и столбцов оказывается выгоднее добавлять в цикле 50 тысяч строк к таблице из 40 тысяч строк, чем наоборот. Возможно, это связано с особенносями выделения памяти для таблицы значений.
4.6 Влияние количества отличий
Ну и, наконец, исследуем зависимость времени сравнения от степени отличия таблиц. Видно, что при увеличении процента расхождений время работы свертки замедляетс. Так как начинает играть роль нелинейность сортировки.

4.7 Влияние оборудования и программного окружения
Тесты выполнялись на платформе 8.3.5.1248 на ноутбуке VGN-Z51MRG. Полученные зависимости в целом подтверждаются на другом оборудовании, но есть и некоторые особенности, обобщить которые пока не удалось.
5. Выводы
5.1. Самый простой метод свертки оказывается в большинстве случаев и наиболее производительным. Его и нужно использовать как универсальный метод, но не в специальных случаях.
5.2 При малом размере (до 50000 строк) можно получить дополнительное ускорение свертки, применив копирование столбцов при объединении таблиц (метод 3.2).
5.3 В специальном случае одной ключевой колонки, значительного количества различий и существенной разницы размеров таблиц следует использовать соединение по соответствию. Так же следует поступать, даже если ключевых таблиц несколько, но сравнение производится с одной и той же таблицей, для которой можно заранее подготовить "дерево решений" на основе соответствия, настроенное на ее особенности.
5.4 В специальном случае нескольких ключевых колонок при значительном количестве различий и не отсортированности сравниваемых таблиц нужно использовать метод соединения по индексу.
5.5 Для наибольшей эффективности методов 1-4 нужно выбирать правильный порядок указания таблиц при сравнении.
5.6 В специальном случае отсортированности сравниваемых таблиц при значительном количестве различий следует использовать слияние.
5.7. В специальном случае больших (зависит от оборудования) и примерно равных по размеру таблиц, которые, к тому же, имеют значительные отличия и состоят из коротких строк и предельно малого числа колонок, возможно использовать запросы.
5.8 Если в таблицах преобладают числовые данные, даты, средние и длинные строки, то в запросах сравнения таблиц следует использовать группировку, и только для очень коротких строк - полное соединение.
6. Общие выводы
6.1 В любом случае перед решающим выбором лучше по-возможности сравнивать несколько методов в реальных условиях их применения. Например, при помощи приложенной к статье обработки.
6.2 Учет особенностей данных в таблицах позволяет произвести целенаправленную дополнительную оптимизацию большинства приведенных методов. Для этого остается немало возможностей, оставшихся за пределами рассмотренного круга вопросов.
6.3 Ввод таблиц значений в запросы может занимать значительное время, что в большинстве случаев сводит на нет эффективность их применения в задачах, когда данные берутся из памяти, а не из базы. Бездумное использование запросов в этой задаче - вредное заблуждение.
6.4 Время работы метода НайтиСтроки при наличии индекса по колонкам, входящим в отбор, не зависит от размера таблицы значений. Таким образом правильной оценкой быстродействия метода сравнения таблиц с использованием соединения по индексу является O(N).
, которые предложили, реализовали и отладили свои методы для одномерного случая, вносили множество полезных поправок и соображений, а также активно участвовали во всех обсуждениях. Отдельное спасибо спонсорам той самой ветки и - за интересный вопрос.Чтение этой статьи займёт у Вас около 10 минут. В следующие 5 минут Вы сможете легко сравнить два столбца в Excel и узнать о наличии в них дубликатов, удалить их или выделить цветом. Итак, время пошло!
Excel – это очень мощное и действительно крутое приложение для создания и обработки больших массивов данных. Если у Вас есть несколько рабочих книг с данными (или только одна огромная таблица), то, вероятно, Вы захотите сравнить 2 столбца, найти повторяющиеся значения, а затем совершить с ними какие-либо действия, например, удалить, выделить цветом или очистить содержимое. Столбцы могут находиться в одной таблице, быть смежными или не смежными, могут быть расположены на 2-х разных листах или даже в разных книгах.
Представьте, что у нас есть 2 столбца с именами людей – 5 имён в столбце A и 3 имени в столбце B . Необходимо сравнить имена в этих двух столбцах и найти повторяющиеся. Как Вы понимаете, это вымышленные данные, взятые исключительно для примера. В реальных таблицах мы имеем дело с тысячами, а то и с десятками тысяч записей.
Вариант А: оба столбца находятся на одном листе. Например, столбец A и столбец B .

Вариант В: Столбцы расположены на разных листах. Например, столбец A на листе Sheet2 и столбец A на листе Sheet3 .

В Excel 2013, 2010 и 2007 есть встроенный инструмент Remove Duplicate (Удалить дубликаты), но он бессилен в такой ситуации, поскольку не может сравнивать данные в 2 столбцах. Более того, он может только удалить дубликаты. Других вариантов, таких как выделение или изменение цвета, не предусмотрено. И точка!
Сравниваем 2 столбца в Excel и находим повторяющиеся записи при помощи формул
Вариант А: оба столбца находятся на одном листе

Подсказка: В больших таблицах скопировать формулу получится быстрее, если использовать комбинации клавиш. Выделите ячейку C1 и нажмите Ctrl+C (чтобы скопировать формулу в буфер обмена), затем нажмите Ctrl+Shift+End (чтобы выделить все не пустые ячейки в столбе С) и, наконец, нажмите Ctrl+V (чтобы вставить формулу во все выделенные ячейки).

Вариант В: два столбца находятся на разных листах (в разных книгах)
Обработка найденных дубликатов
Отлично, мы нашли записи в первом столбце, которые также присутствуют во втором столбце. Теперь нам нужно что-то с ними делать. Просматривать все повторяющиеся записи в таблице вручную довольно неэффективно и занимает слишком много времени. Существуют пути получше.
Показать только повторяющиеся строки в столбце А
Если Ваши столбцы не имеют заголовков, то их необходимо добавить. Для этого поместите курсор на число, обозначающее первую строку, при этом он превратится в чёрную стрелку, как показано на рисунке ниже:

Кликните правой кнопкой мыши и в контекстном меню выберите Insert (Вставить):

Дайте названия столбцам, например, “Name ” и “Duplicate? ” Затем откройте вкладку Data (Данные) и нажмите Filter (Фильтр):

После этого нажмите меленькую серую стрелку рядом с “Duplicate? “, чтобы раскрыть меню фильтра; снимите галочки со всех элементов этого списка, кроме Duplicate , и нажмите ОК .

Вот и всё, теперь Вы видите только те элементы столбца А , которые дублируются в столбце В . В нашей учебной таблице таких ячеек всего две, но, как Вы понимаете, на практике их встретится намного больше.

Чтобы снова отобразить все строки столбца А , кликните символ фильтра в столбце В , который теперь выглядит как воронка с маленькой стрелочкой и выберите Select all (Выделить все). Либо Вы можете сделать то же самое через Ленту, нажав Data (Данные) > Select & Filter (Сортировка и фильтр) > Clear (Очистить), как показано на снимке экрана ниже:

Изменение цвета или выделение найденных дубликатов
Если пометки “Duplicate ” не достаточно для Ваших целей, и Вы хотите отметить повторяющиеся ячейки другим цветом шрифта, заливки или каким-либо другим способом…
В этом случае отфильтруйте дубликаты, как показано выше, выделите все отфильтрованные ячейки и нажмите Ctrl+1 , чтобы открыть диалоговое окно Format Cells (Формат ячеек). В качестве примера, давайте изменим цвет заливки ячеек в строках с дубликатами на ярко-жёлтый. Конечно, Вы можете изменить цвет заливки при помощи инструмента Fill (Цвет заливки) на вкладке Home (Главная), но преимущество диалогового окна Format Cells (Формат ячеек) в том, что можно настроить одновременно все параметры форматирования.

Теперь Вы точно не пропустите ни одной ячейки с дубликатами:

Удаление повторяющихся значений из первого столбца
Отфильтруйте таблицу так, чтобы показаны были только ячейки с повторяющимися значениями, и выделите эти ячейки.
Если 2 столбца, которые Вы сравниваете, находятся на разных листах , то есть в разных таблицах, кликните правой кнопкой мыши выделенный диапазон и в контекстном меню выберите Delete Row (Удалить строку):

Нажмите ОК , когда Excel попросит Вас подтвердить, что Вы действительно хотите удалить всю строку листа и после этого очистите фильтр. Как видите, остались только строки с уникальными значениями:

Если 2 столбца расположены на одном листе , вплотную друг другу (смежные) или не вплотную друг к другу (не смежные), то процесс удаления дубликатов будет чуть сложнее. Мы не можем удалить всю строку с повторяющимися значениями, поскольку так мы удалим ячейки и из второго столбца тоже. Итак, чтобы оставить только уникальные записи в столбце А , сделайте следующее:

Как видите, удалить дубликаты из двух столбцов в Excel при помощи формул – это не так уж сложно.
Сравним две таблицы имеющих практически одинаковую структуру. Таблицы различаются значениями в отдельных строках, некоторые наименования строк встречаются в одной таблице, но в другой могут отсутствовать.
Пусть на листах Январь и Февраль имеется две таблицы с оборотами за период по соответствующим счетам.

Как видно из рисунков, таблицы различаются:
- Наличием (отсутствием) строк (наименований счетов). Например, в таблице на листе Январь отсутствует счет 26 (см. файл примера ), а в таблице на листе Февраль отсутствуют счет 10 и его субсчета.
- Разными значениями в строках. Например, по счету 57 обороты за январь и февраль не совпадают.
Если структуры таблиц примерно одинаковы (большинство наименований счетов (строк) совпадают, количество и наименования столбцов совпадают), то можно сравнить две таблицы. Проведем сравнение двумя способами: один проще в реализации, другой нагляднее.
Простой вариант сравнения 2-х таблиц
Сначала определим какие строки (наименования счетов) присутствуют в одной таблице, но отсутствуют в другой. Затем, в таблице, в которой меньше строк отсутствует (в наиболее полной таблице), выведем отчет о сравнении, представляющий собой разницу по столбцам (разница оборотов за январь и февраль).
Основным недостатком этого подхода является, то, что отчет о сравнении таблиц не включает строки отсутствующие в наиболее полной таблице. Например, в рассматриваемом нами случае, наиболее полной таблицей является таблица на листе Январь, в которой отсутствует счет 26 из февральской таблицы.

Чтобы определить какая из двух таблиц является наиболее полной нужно ответить на 2 вопроса: Какие счета в февральской таблице отсутствуют в январской? и Какие счета в январской таблице отсутствуют в январской?
Это можно сделать с помощью формул (см. столбец Е): =ЕСЛИ(ЕНД(ВПР(A7;Январь!$A$7:$A$81;1;0));"Нет";"Есть") и =ЕСЛИ(ЕНД(ВПР(A7;Февраль!$A$7:$A$77;1;0));"Нет";"Есть")
Сравнение оборотов по счетам произведем с помощью формул: =ЕСЛИ(ЕНД(ВПР($A7;Февраль!$A$7:$C77;2;0));0;ВПР($A7;Февраль!$A$7:$C77;2;0))-B7 и =ЕСЛИ(ЕНД(ВПР($A7;Февраль!$A$7:$C77;3;0));0;ВПР($A7;Февраль!$A$7:$C77;3;0))-C7
В случае отсутствия соответствующей строки функция ВПР() возвращает ошибку #Н/Д, которая обрабатывается связкой функций ЕНД() и ЕСЛИ() , заменяя ошибку на 0 (в случае отсутствия строки) или на значение из соответствующего столбца.
С помощью можно выделить расхождения (например, красным цветом).
Более наглядный вариант сравнения 2-х таблиц (но более сложный)
По аналогии с задачей решенной в статье можно сформировать список наименований счетов, включающий ВСЕ наименования счетов из обоих таблиц (без повторов). Затем вывести разницу по столбцам.

Для этого необходимо:
- С помощью =ЕСЛИОШИБКА(ЕСЛИОШИБКА(ИНДЕКС(Январь;ПОИСКПОЗ(0;СЧЁТЕСЛИ(A$4:$A4;Январь);0)); ИНДЕКС(Февраль;ПОИСКПОЗ(0;СЧЁТЕСЛИ(A$4:$A4;Февраль);0)));"") сформировать в столбце А перечень счетов из обоих таблиц (без повторов);
- С помощью =ЕСЛИОШИБКА(ИНДЕКС(Список; ПОИСКПОЗ(НАИМЕНЬШИЙ(СЧЁТЕСЛИ(Список; "<"&Список); СТРОКА()-СТРОКА($B$4)); СЧЁТЕСЛИ(Список; "<"&Список); 0));"") , где Список - представляет собой перечень счетов из обоих таблиц (столбец А), счетов, полученный на предыдущем этапе;
- С помощью формулы =ЕСЛИ(ЕНД(ВПР($B5;Январь!$A$7:$C$81;2;0));0;ВПР($B5;Январь!$A$7:$C$81;2;0))- ЕСЛИ(ЕНД(ВПР($B5;Февраль!$A$7:$C$77;2;0));0;ВПР($B5;Февраль!$A$7:$C$77;2;0)) произвести сравнение оборотов по счетам;
- С помощью выделить расхождения цветом, а также выделить счета встречающиеся только в одной таблице (например, на рисунке выше счета, содержащиеся только в таблице Январь, выделены синим, а желтым выделены счета только из февральской таблицы).
Открытие бизнеса

Где можно и где нельзя работать после туберкулеза Где можно работать после
Форекс
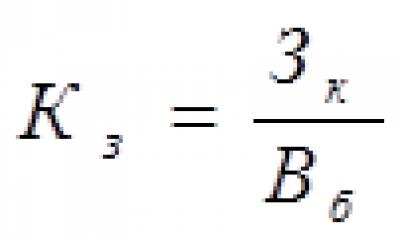
Направления повышения эффективности использования собственного капитала На базе двигателя с плоским печатным якорем разработаны изделия для автомобильной промышленности
Банки




