Если выбранная в качестве объясняющей переменной величина представляет собой действительно доминирующий фактор, то соответствующая парная регрессия достаточно полно описывает механизм причинно-следственной связи. Часто изменение y связано с влиянием не одного, а нескольких факторов. В этом случае в уравнение регрессии вводятся несколько объясняющих переменных. Такая регрессия называется множественной. Уравнение множественной регрессии позволяет лучше, полнее объяснить поведение зависимой переменной, чем парная регрессия, кроме того, оно дает возможность сопоставить эффективность влияния различных факторов.
Линейная модель множественной регрессии имеет вид:
где m – количество включенных в модель факторов. Коэффициент регрессии показывает, на какую величину в среднем изменится результативный признак y , если переменную увеличить на единицу измерения, т.е. является нормативным коэффициентом.
Уравнение линейной модели множественной регрессии в матричном виде имеет вид:
![]() , (7.11)
, (7.11)
где Y n х1 наблюдаемых значений зависимой переменной;
X – матрица размерности n х(m+1) наблюдаемых значений независимых переменных (дополнительно вводится фактор, состоящий из одних единиц для вычисления свободного члена);
α – вектор-столбец размерности (m+1) х1 неизвестных, подлежащих оценке коэффициентов регрессии;
ε – вектор-столбец размерности n х1 случайных отклонений.
Таким образом,
, , ,.
, ,.
При применении МНК относительно случайной составляющей в модели (7.10) принимаются предположения, которые являются аналогами предположений, сделанных выше для МНК, применяемого при оценивании параметров парной регрессии. Обычно предполагается:
1. ![]() - детерминированные переменные.
- детерминированные переменные.
2. ![]() - математическое ожидание случайной составляющей в любом наблюдении равно нулю.
- математическое ожидание случайной составляющей в любом наблюдении равно нулю.
3. - дисперсия случайного члена постоянна для всех наблюдений.
4. - в любых двух наблюдениях отсутствует систематическая связь между значениями случайной составляющей.
5. ~ - часто добавляется условие о нормальности распределения случайного члена.
Модель линейной множественной регрессии, для которой выполняются данные предпосылки, называется классической нормальной регрессионной моделью (Classical Normal Regression model).
Гипотезы, лежащие в основе модели множественной регрессии удобно записать в матричной форме:
1. Х – детерминированная матрица, имеет максимальный ранг (m+1)
, ρ(Х)=m+1
3,4. ![]() , где I n
– единичная матрица размером n
xn
. Так как ε
- вектор-столбец, размерности n
х1
, а ε Т
– вектор-строка, произведение εε Т
есть симметрическая матрица порядка n
. Матрица ковариаций:
, где I n
– единичная матрица размером n
xn
. Так как ε
- вектор-столбец, размерности n
х1
, а ε Т
– вектор-строка, произведение εε Т
есть симметрическая матрица порядка n
. Матрица ковариаций:
 ,
,
Элементы, стоящие на главной диагонали, свидетельствуют о том, что для всех i , это означает, что все имеют постоянную дисперсию . Элементы, не стоящие на главной диагонали дают нам для , так что значения попарно некоррелированы.
Цель : необходимо научиться определять параметры уравнения множественной линейной регрессии, используя метод наименьших квадратов (МНК), рассчитывать коэффициент множественной корреляции.
Ключевые слова : линейная модель множественной регрессии, матрица парных коэффициентов корреляции, коэффициент множественной детерминации, индекс корреляции.
План лекции:
1. Классическая нормальная линейная модель множественной регрессии.
2. Оценка параметров линейной модели множественной регрессии.
3. Множественная и частная корреляция.
1.Классическая нормальная линейная модель множественной регрессии.
Экономические явления, как правило, определяются большим числом одновременно действующих факторов. В качестве примера такой связи можно рассматривать зависимость доходности финансовых активов от следующих факторов: темпов прироста ВВП, уровня процентных ставок, уровня инфляции и уровня цен на нефть.
В связи с этим возникает задача исследования зависимости одной зависимой переменной у от нескольких объясняющих факторных переменных х 1 , х 2 ,…, х n , оказывающих на нее влияние. Эта задача решается с помощью множественного регрессионного анализа .
Как и в парной зависимости, используются разные виды уравнений множественной регрессии: линейные и нелинейные.
Ввиду четкой интерпретации параметров наиболее широко используются линейная и степенная функции.
В линейной множественной регрессии параметры при количественной объясняющей переменной интерпретируется как среднее изменение результирующей переменной при единичном изменении самой объясняющей переменной и неизменных значениях остальных независимых переменных.
Пример. Предположим, что зависимость расходов на продукты питания по совокупности семей характеризуется следующим уравнением:
где у – расходы семьи за месяц на продукты питания, тыс.тг.
х 1 – среднемесячный доход на одного члена семьи, тыс.тг.
х 2 – размер семьи, человек.
Анализ данного уравнения позволяет сделать выводы – с ростом дохода на одного члена семьи на 1 тыс.тг. расходы на питание возрастут в среднем на 350 тг. при том же размере семьи. Иными словами, 35% дополнительных семейных расходов тратится на питание. Увеличение размера семьи при тех же доходах предполагает дополнительный рост расходов на питание на 730 тг.
В степенной функции ![]() коэффициенты b j являются коэффициентами эластичности. Они показывают, на сколько процентов в среднем изменяется результат с изменением соответствующего фактора на 1% при неизменности действия других факторов.
коэффициенты b j являются коэффициентами эластичности. Они показывают, на сколько процентов в среднем изменяется результат с изменением соответствующего фактора на 1% при неизменности действия других факторов.
Пример. Предположим, что при исследовании спроса на мясо получено уравнение
![]() ,
,
где у – количество спроса на мясо,
х 1 – цена,
х 2 – доход.
Следовательно, рост цен на 1% при том же доходе вызывает снижение спроса в среднем на 2,63%. Увеличение дохода на 1% обуславливает при неизменных ценах рост спроса на 1,11%.
где b 0 , b 1 ,…,b k – параметры модели, а ε – случайный член, называется классической нормальной линейной регрессионной моделью , если выполняются следующие условия (называемые условиями Гаусса-Маркова):
1. Математическое ожидание случайного члена в любом наблюдении должно быть равно нулю, т.е. .
2. Дисперсия случайного члена должна быть постоянной для всех наблюдений, т.е. .
3. Случайные члены должны быть статистически независимы (некоррелированы) между собой, ![]() .
.
4. - есть нормально распределенная случайная величина.
2.Оценка параметров линейной модели множественной регрессии.
Параметры уравнения множественной регрессии оцениваются методом наименьших квадратов. При его применении строится система нормальных уравнений, решение которой позволяет получить оценки параметров регрессии.
Так, для уравнения система нормальных уравнений составит:

Ее решение может быть осуществлено методом Крамера:
![]() ,
,
где ∆ - определитель системы,
Частные определители.
 ,
,
а получаются путем замены соответствующего столбца определителя системы столбцом свободных членов.
Рассмотрим линейную модель зависимости результативного признака у от двух факторных признаков и . Эта модель имеет вид:
![]()
Для нахождения параметров и решается система нормальных уравнений:

3.Множественная и частная корреляция.
Многофакторная система требует множество показателей тесноты связей, имеющих разный смысл и применение. Основой измерения связей факторными признаками является матрица парных коэффициентов корреляции, которые определяются по формуле:

На основе парных коэффициентов корреляции вычисляется наиболее общий показатель тесноты связи всех входящих в уравнение регрессии факторов с результирующим признаком – коэффициент множественной детерминации как частное от деления определителя матрицы на опрделитель матрицы ∆: , где
 ;
;
 .
.
Этим способом можно определить коэффициент детерминации, не вычисляя расчетных значений результативного признака для всех единиц совокупности, если совокупность состоит из сотен и тысяч единиц.
Множественный регрессионный анализ является расширением парного регрессионного анализа. О применяется в тех случаям, когда поведение объясняемой, зависимой переменной необходимо связать с влиянием более чем одной факторной, независимой переменной. Хотя определенная часть многофакторного анализа представляет собой непосредственное обобщение понятий парной регрессионной модели, при выполнении его может возникнуть ряд принципиально новых задач.
Так, при оценке влияния каждой независимой переменной необходимо уметь разграничивать ее воздействие на объясняемую переменную от воздействия других независимых переменных. При этом множественный корреляционный анализ сводится к анализу парных, частных корреляций. На практике обычно ограничиваются определением их обобщенных числовых характеристик, таких как частные коэффициенты эластичности, частные коэффициенты корреляции, стандартизованные коэффициенты множественной регрессии.
Затем решаются задачи спецификации регрессионной модели, одна из которых состоит в определении объема и состава совокупности независимых переменных, которые могут оказывать влияние на объясняемую переменную. Хотя это часто делается из априорных соображений или на основании соответствующей экономической (качественной) теории, некоторые переменные могут в силу индивидуальных особенностей изучаемых объектов не подходить для модели. В качестве наиболее характерных из них можно назвать мультиколлинеарность или автокоррелированность факторных переменных.
3.1. Анализ множественной линейной регрессии с помощью
метода наименьших квадратов (МНК)
В данном разделе полагается, что рассматривается модель регрессии, которая специфицирована правильно. Обратное, если исходные предположения оказались неверными, можно установить только на основании качества полученной модели. Следовательно, этот этап является исходным для проведения множественного регрессионного анализа даже в самом сложном случае, поскольку только он, а точнее его результаты могут дать основания для дальнейшего уточнения модельных представлений. В таком случае выполняются необходимые изменения и дополнения в спецификации модели, и анализ повторяется после уточнения модели до тех пор, пока не будут получены удовлетворительные результаты.
На любой экономический показатель в реальных условиях обычно оказывает влияние не один, а несколько и не всегда независимых факторов. Например, спрос на некоторый вид товара определяется не только ценой данного товара, но и ценами на замещающие и дополняющие товары, доходом потребителей и многими другими факторами. В этом случае вместо парной регрессии M (Y / Х = х ) = f (x ) рассматривается множественная регрессия
M (Y / Х1 = х1, Х2 = х2, …, Хр = Хр ) = f (x 1 , х 2 , …, х р ) (2.1)
Задача оценки статистической взаимосвязи переменных Y и Х 1 , Х 2 , ..., Х Р формулируется аналогично случаю парной регрессии. Уравнение множественной регрессии может быть представлено в виде
Y = f (B , X ) + 2
где X - вектор независимых (объясняющих) переменных; В - вектор параметров уравнения (подлежащих определению); - случайная ошибка (отклонение); Y - зависимая (объясняемая) переменная.
Предполагается, что для данной генеральной совокупности именно функция f связывает исследуемую переменную Y с вектором независимых переменных X .
Рассмотрим самую употребляемую и наиболее простую для статистического анализа и экономической интерпретации модель множественной линейной регрессии. Для этого имеются, по крайней мере, две существенные причины.
Во-первых, уравнение регрессии является линейным, если система случайных величин (X 1 , X 2 , ..., Х Р , Y ) имеет совместный нормальный закон распределения. Предположение о нормальном распределении может быть в ряде случаев обосновано с помощью предельных теорем теории вероятностей. Часто такое предположение принимается в качестве гипотезы, когда при последующем анализе и интерпретации его результатов не возникает явных противоречий.
Вторая причина, по которой линейная регрессионная модель предпочтительней других, состоит в том, что при использовании ее для прогноза риск значительной ошибки оказывается минимальным.
Теоретическое линейное уравнение регрессии имеет вид:
или для индивидуальных наблюдений с номером i :
где i = 1, 2, ..., п.
Здесь В = (b 0 , b 1 ,b Р) - вектор размерности (р+1) неизвестных параметров b j , j = 0, 1, 2, ..., р , называется j -ым теоретическим коэффициентом регрессии (частичным коэффициентом регрессии). Он характеризует чувствительность величины Y к изменению X j . Другими словами, он отражает влияние на условное математическое ожидание M (Y / Х1 = х1, Х2 = х2, …, Хр = x р ) зависимой переменной Y объясняющей переменной Х j при условии, что все другие объясняющие переменные модели остаются постоянными. b 0 - свободный член, определяющий значение Y в случае, когда все объясняющие переменные X j равны нулю.
После выбора линейной функции в качестве модели зависимости необходимо оценить параметры регрессии.
Пусть имеется n наблюдений вектора объясняющих переменных X = (1 , X 1 , X 2 , ..., Х Р ) и зависимой переменной Y :
(1 , х i1 , x i2 , …, x ip , y i ), i = 1, 2, …, n.
Для того чтобы однозначно можно было бы решить задачу отыскания параметров b 0 , b 1 , … , b Р (т.е. найти некоторый наилучший вектор В ), должно выполняться неравенство n > p + 1 . Если это неравенство не будет выполняться, то существует бесконечно много различных векторов параметров, при которых линейная формула связи между X и Y будет абсолютно точно соответствовать имеющимся наблюдениям. При этом, если n = p + 1 , то оценки коэффициентов вектора В рассчитываются единственным образом - путем решения системы p + 1 линейного уравнения:
где i = 1, 2, ..., п.
Например, для однозначного определения оценок параметров уравнения регрессии Y = b о + b 1 X 1 + b 2 X 2 достаточно иметь выборку из трех наблюдений (1 , х i 1 , х i 2 , y i), i = 1, 2, 3. В этом случае найденные значения параметров b 0 , b 1 , b 2 определяют такую плоскость Y = b о + b 1 X 1 + b 2 X 2 в трехмерном пространстве, которая пройдет именно через имеющиеся три точки.
С другой стороны, добавление в выборку к имеющимся трем наблюдениям еще одного приведет к тому, что четвертая точка (х 41 , х 42 , х 43 , y 4) практически всегда будет лежать вне построенной плоскости (и, возможно, достаточно далеко). Это потребует определенной переоценки параметров.
Таким образом, вполне логичен следующий вывод: если число наблюдений больше минимально необходимой величины, т.е. n > p + 1 , то уже нельзя подобрать линейную форму, в точности удовлетворяющую всем наблюдениям. Поэтому возникает необходимость оптимизации, т.е. оценивания параметров b 0 , b 1 , …, b Р , при которых формула регрессии дает наилучшее приближение одновременно для всех имеющихся наблюдений.
В данном случае число = n - p - 1 называется числом степеней свободы. Нетрудно заметить, что если число степеней свободы невелико, то статистическая надежность оцениваемой формулы невысока. Например, вероятность надежного вывода (получения наиболее реалистичных оценок) по трем наблюдениям существенно ниже, чем по тридцати. Считается, что при оценивании множественной линейной регрессии для обеспечения статистической надежности требуется, чтобы число наблюдений превосходило число оцениваемых параметров, по крайней мере, в 3 раза.
Прежде чем перейти к описанию алгоритма нахождения оценок коэффициентов регрессии, отметим желательность выполнимости ряда предпосылок МНК, которые позволят обосновать характерные особенности регрессионного анализа в рамках классической линейной многофакторной модели.
Ответы на экзаменационные билеты по эконометрике Яковлева Ангелина Витальевна
26. Линейная модель множественной регрессии
Построение модели множественной регрессии является одним из методов характеристики аналитической формы связи между зависимой (результативной) переменной и несколькими независимыми (факторными) переменными.
Модель множественной регрессии строится в том случае, если коэффициент множественной корреляции показал наличие связи между исследуемыми переменными.
Общий вид линейной модели множественной регрессии:
yi=?0+?1x1i+…+?mxmi+?i,
где yi – значение i-ой результативной переменной,
x1i…xmi – значения факторных переменных;
?0…?m – неизвестные коэффициенты модели множественной регрессии;
?i – случайные ошибки модели множественной регрессии.
При построении нормальной линейной модели множественной регрессии учитываются пять условий:
1) факторные переменные x1i…xmi – неслучайные или детерминированные величины, которые не зависят от распределения случайной ошибки модели регрессии ?i;
![]()
3) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:
4) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т.е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):
Это условие выполняется в том случае, если исходные данные не являются временными рядами;
5) на основании третьего и четвёртого условий часто добавляется пятое условие, заключающееся в том, что случайная ошибка модели регрессии – это случайная величина, подчиняющейся нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2: ?i~N(0, G2).
Общий вид нормальной линейной модели парной регрессии в матричной форме:
Y=X* ?+?,

– случайный вектор-столбец значений результативной переменной размерности (n*1);

– матрица значений факторной переменной размерности (n*(m+1)). Первый столбец является единичным, потому что в модели регрессии коэффициент ?0 умножается на единицу;

– вектор-столбец неизвестных коэффициентов модели регрессии размерности ((m+1)*1);

– случайный вектор-столбец ошибок модели регрессии размерности (n*1).
Включение в линейную модель множественной регрессии случайного вектора-столбца ошибок модели обусловлено тем, что практически невозможно оценить связь между переменными со 100-процентной точностью.
Условия построения нормальной линейной модели множественной регрессии, записанные в матричной форме:
1) факторные переменные x1j…xmj
– неслучайные или детерминированные величины, которые не зависят от распределения случайной ошибки модели регрессии ?i
. В терминах матричной записи Х
называется детерминированной матрицей ранга (k+1),
т.е. столбцы матрицы X
линейно независимы между собой и ранг матрицы Х
равен m+1
![]()
2) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
3) предположения о том, что дисперсия случайной ошибки модели регрессии является постоянной для всех наблюдений и ковариация случайных ошибок любых двух разных наблюдений равна нулю, записываются с помощью ковариационной матрицы случайных ошибок нормальной линейной модели множественной регрессии:

G2 – дисперсия случайной ошибки модели регрессии?;
In – единичная матрица размерности (n*n ).
4) случайная ошибка модели регрессии? является независимой и независящей от матрицы Х случайной величиной, подчиняющейся многомерному нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2: ??N(0;G2In.
В нормальную линейную модель множественной регрессии должны входить факторные переменные, удовлетворяющие следующим условиям:
1) данные переменные должны быть количественно измеримыми;
2) каждая факторная переменная должна достаточно тесно коррелировать с результативной переменной;
3) факторные переменные не должны сильно коррелировать друг с другом или находиться в строгой функциональной зависимости.
Из книги Большая Советская Энциклопедия (ЛИ) автора БСЭ Из книги Пикап. Самоучитель по соблазнению автора Богачев Филипп Олегович Из книги Ответы на экзаменационные билеты по эконометрике автора Яковлева Ангелина Витальевна Из книги автора Из книги автора Из книги автора9. Общая модель парной (однофакторной) регрессии Общая модель парной регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем в целом по совокупности наблюдений.Регрессионным анализом называется
Из книги автора10. Нормальная линейная модель парной (однофакторной) регрессии Общий вид нормальной (традиционной или классической) линейной модели парной (однофакторной) регрессии (Classical Normal Regression Model):yi=?0+?1xi+?i,где yi– результативные переменные, xi – факторные переменные, ?0, ?1 – параметры
Из книги автора14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии Помимо метода наименьших квадратов, с помощью которого в большинстве случаев определяются неизвестные параметры модели регрессии, в случае линейной модели парной регрессии
Из книги автора27. Классический метод наименьших квадратов для модели множественной регрессии. Метод Крамера В общем виде линейную модель множественной регрессии можно записать следующим образом:yi=?0+?1x1i+…+?mxmi+?i, где yi – значение i-ой результативной переменной,x1i…xmi – значения факторных
Из книги автора28. Линейная модель множественной регрессии стандартизированного масштаба Помимо классического метода наименьших квадратов для определения неизвестных параметров линейной модели множественной регрессии?0…?m используется метод оценки данных параметров через
Из книги автора31. Частные коэффициенты корреляции для модели множественной регрессии с тремя и более факторными переменными Частные коэффициенты корреляции для модели множественной регрессии с тремя и более факторными переменными позволяют определить степень зависимости между
Из книги автора32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации Помимо рекуррентных формул, которые используются для построения частных коэффициентов корреляции для
Из книги автора33. Коэффициент множественной корреляции. Коэффициент множественной детерминации Если частные коэффициенты корреляции модели множественной регрессии оказались значимыми, т. е. между результативной переменной и факторными модельными переменными действительно
Из книги автора35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом Проверка значимости коэффициентов регрессии означает проверку основной гипотезы об их значимом отличии от нуля.Основная гипотеза состоит в предположении о незначимости
Из книги автора46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все
Из книги автора65. Обобщённая модель регрессии. Обобщённый метод наименьших квадратов. Теорема Айткена МНК-оценки неизвестных коэффициентов модели регрессии, чьи случайные ошибки подвержены явлениям гетероскедастичности или автокорреляции, не будут удовлетворять теореме
4.1. Матричная форма регрессионной модели
Экономическое явление определяется большим числом одновременно и совокупно действующих факторов. Модель множественной регрессии запишется так:

Модель линейной множественной регрессии можно записать в матричной форме, имея в виду, что коэффициенты α и β заменены их оценками.





Матрица X T X – неособенная и её ранг равен её размеру, то есть (р +1).
4.2. Отбор факторов для моделей множественной регрессии
Факторы, включаемые в модель, должны существенным образом объяснить вариацию результативной переменной.
Существует ряд способов отбора факторов, наибольшее распространение из которых имеют метод короткой регрессии и метод длинной регрессии.
При использовании метода короткой регрессии в начале в модель включают только наиболее важные факторы с экономически содержательной точки зрения.
С этим набором факторов строится модель и для неё определяются показатели качества ESS , R 2 , F , t a , t bj . Затем в модель добавляется следующий фактор и вновь строится модель. Проводится анализ, улучшилась или ухудшилась модель по совокупности критериев. При этом возможно появление парето – оптимальных альтернатив.
Метод длинной регрессии предполагает первоначальное включение в модель всех подозрительных на существенность факторов. Затем какой-либо фактор исключают из модели и анализируют изменение её качества. Если качество улучшится, фактор удаляют и наоборот. При отборе факторов следует обращать внимание на наличие интеркорреляции и мультиколлинеарности.
Сильная корреляция между двумя факторами (интеркорреляция) не позволяет выявить изолированное влияние каждого из них на результативную переменную, то есть затрудняется интерпретация параметров регрессии и они утрачивают истинный экономический смысл. Оценки значений этих параметров становятся ненадёжными и будут иметь большие стандартные ошибки. При изменении объёма наблюдений они могут сильно изменяться, причём не только по величине, но даже и по знаку.
Мультиколлинеарность – явление, когда сильной линейной зависимостью связаны более двух переменных; она приводит к тем же негативным последствиям, о которых только что было сказано. Поэтому, при отборе факторов следует избегать наличия интеркорреляции и, тем более, мультиколлинеарности.
Для обнаружения интеркорреляции и мультиколлинеарности можно использовать анализ матрицы парных коэффициентов корреляции [r (п) ], матрицы межфакторной корреляции [r (11) ] и матрицы частных коэффициентов корреляции [r (ч) ].

Для исключения одного из двух сильно коррелирующих между собой факторов можно руководствоваться таким соображением: из модели бывает целесообразно убрать не тот фактор, который слабее связан с y , а тот, который сильнее связан с другими факторами. Это приемлемо, если связь с y для обоих факторов приблизительно одинакова. При этом возможно наличие парето – оптимальных альтернатив и тогда следует рассмотреть иные аргументы в пользу того или иного фактора.
Матрица [r (11) ] – получается путём вычёркивания первого столбца и первой строки из матрицы [r (п) ].
Матрица [r (11) ] – квадратная и неособенная, ее элементы вычисляются так:

Представляется интересным исследовать определитель det [r (11) ].
Если есть сильная мультиколлинеарность, то почти все элементы этой матрицы близки к единице и det → 0. Если все факторы практически независимы, то в главной диагонали будут стоять величины, близкие к единице, а прочие элементы будут близки к нулю, тогда det→1.
Таким образом, численное значение det [r (11) ] позволяет установить наличие или отсутствие мультиколлинеарности. Мультиколлинеарность может иметь место вследствие того, что какой-либо фактор является линейной (или близкой к ней) комбинацией других факторов.
Для выявления этого обстоятельства можно построить регрессии каждой объясняющей переменной на все остальные. Далее вычисляются соответствующие коэффициенты детерминации

и рассчитывается статистическая значимость каждой такой регрессии по F –статистике:

Критическое значение F определяется по таблице для назначенного уровня значимости γ (вероятности отвергнуть верную гипотезу Н 0 о незначимости R 2), и числа степеней свободы df 1 = p –1, df 2 = n –1.
Оценку значимости мультиколлинеарности можно также произвести путём проверки гипотезы об её отсутствии: Н
0: det [r
(11) ] =1. Доказано, что величина:  приближённо имеет распределение Пирсона: Если вычисленное значение χ
2 превышает табличное значение для назначенного γ
и df
= n
(n
–1)/2, то гипотеза Н
0 отклоняется и мультиколлинеарность считается установленной.
приближённо имеет распределение Пирсона: Если вычисленное значение χ
2 превышает табличное значение для назначенного γ
и df
= n
(n
–1)/2, то гипотеза Н
0 отклоняется и мультиколлинеарность считается установленной.
Парные коэффициенты корреляции не всегда объективно показывают действительную связь между факторами. Например, факторы могут по существу явления не быть связаны между собой, но смещаться в одну сторону под влиянием некоторого стороннего фактора, не включенного в модель. Довольно часто таким фактором выступает время. Поэтому включение (если это возможно) в модель переменной t иногда снижает степень интеркорреляции и мультиколлинеарности. Более адекватными показателями межфакторной корреляции являются частные коэффициенты корреляции. Они отражают тесноту статистической связи между двумя переменными при элиминировании влияния других факторов.
Здесь b 1 будет являться несмещенной оценкой параметра β 1 , а b 2 будет несмещенной оценкой нуля (при выполнении условий Гаусса-Маркова).
Утрата эффективности в связи с включением x 2 в случае, когда она не должна быть включена, зависит от корреляции между x 1 и x 2 .
Сравним (см. табл. 4.1).
Открытие бизнеса

Где можно и где нельзя работать после туберкулеза Где можно работать после
Форекс
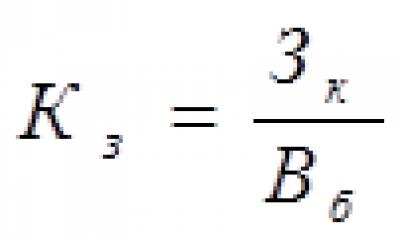
Направления повышения эффективности использования собственного капитала На базе двигателя с плоским печатным якорем разработаны изделия для автомобильной промышленности
Банки




