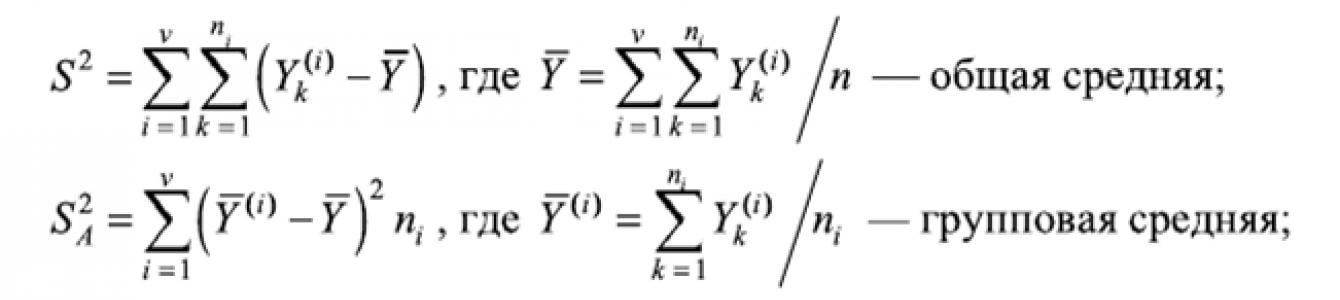
Дисперсионный анализ используется для выявления влияния на изучаемый показатель некоторых факторов, обычно не поддающихся количественному измерению. Суть метода состоит в разложении общей вариации изучаемого показателя на части, соответствующие раздельному и совместному влиянию факторов, и статистическом изучении этих частей с целью выяснения приемлемости гипотез об отсутствии этих влияний. Модели дисперсионного анализа в зависимости от числа факторов классифицируются на однофакторные , двухфакторные и т.д. По цели исследования выделяют следующие модели: детерминированная (Ml) - здесь уровни всех факторов заранее фиксированы, и проверяют именно их влияние, случайная (М2) - здесь уровни каждого фактора получены как случайная выборка из генеральной совокупности уровней фактора, и смешанная (М3) - здесь уровни одних факторов заранее фиксированы, а уровни других - случайная выборка.
Однофакторный дисперсионный анализ
В основе однофакторного дисперсионного анализа лежит следующая вероятностная модель:
где - значение случайной величины У, принимаемое при уровне Д (,) , / =
1,2,..., v, фактора Л в &-м наблюдении, к = 1,2, ..., п,;
О 1 " 1 - эффект влияния на УГ уровня Д®;
е® - независимые случайные величины, отражающие влияние на У/"* неконтролируемых остаточных факторов, причем все е* 1 ~ N(0, o R).
При этом в модели Ml все 0 (,) - детерминированные величины
и?е ("Ч = 0 ; а в модели М2 0 (,) - случайные величины (значения слу-
чайного эффекта 0), 0® = 0 где 0 - ;V(0, ст в), и все 0® и е* ’ - независимы.
Найдем общую вариацию S 2
результативного признака У и две ее составляющие - S 2 A
и S R
, отражающие соответственно влияние фактора А
и влияние остаточных факторов:

Нетрудно убедиться в том, что S 2 = S 2 A + . Разделив все части
этого равенства на я, получим:
Это правило читается так: «Общая дисперсия наблюдений равна сумме межгрупповой дисперсии (это дисперсия Су (0 групповых средних) и внутригрупповой дисперсии (это средняя а 2 из групповых дисперсий)».
Для выяснения того, влияет ли фактор А на результативный признак:
- ? в модели Ml проверяют гипотезу Н 0 : 0 (|) = 0 (2) = ... = 0 (v) =0 (если она будет принята, то для всех ink математическое ожидание МУ/"* = А/У [см. формулу (8.4.1)], а это означает, что при изменении уровня фактора групповая генеральная средняя не изменяется, т.е. рассматриваемые уровни фактора А не влияют на У;
- ? в модели М2 проверяют гипотезу Н 0 = 0 (ее принятие означает что эффект 0 - постоянная величина, а с учетом условия М0 = 0 получим, что 0 = 0, т.е. фактор А не влияет на У).
Критерии проверки этих и других гипотез, а также оценки параметров модели (8.4.1) приведены в табл. 8.5.
Задача 8.7. Исследователь хочет выяснить, отличаются ли четыре способа рекламирования товара по влиянию на объем его продажи. Для этого в каждом из четырех однотипных городов (в них использовались различные способы рекламы) были собраны сведения об объемах продажи товара (в денежных единицах) в четырех случайно отобранных магазинах и вычислены соответствующие выборочные характеристики:
Решение. Здесь фактором А является способ рекламы; зафиксированы четыре его уровня, и выясняется, различаются ли по своему влиянию именно эти уровни, - это модель Ml однофакторного анализа.
где е** независимый?** N(0,g r).
Так как MY и все 0 (,) - постоянные величины, то при выполнении (8.4.3) наблюдения независимы и все
Допустим, что независимость наблюдений гарантируется организацией эксперимента; условие же (8.4.4) означает, что объем продаж при г"-м способе рекламы имеет нормальный закон распределения с математическим ожиданием а, = MY + 0 (,) и с дисперсией, одинаковой для всех способов. Допустим, что нормальное распределение имеет место. Используя критерий Бартлетта (см. табл. 8.3), убедимся, что результаты испытаний позволяют принять гипотезу Н"п : о? =... = ol. Вычислим

по табл. П. 6.3 при k=v-l=3np=a= 0,05 найдем % 2 а = Ха = 7,82 ; так как 1,538 Н" 0 принимаем.
Теперь проверим ключевую гипотезу дисперсионного анализа Н 0
: 0 м =... = 0 S 2 A = 220,19, S 2 R
=39,27, S" 2 = 259,46; убедившись в справедливости равенства (8.4.2), найдем оценку (8.4.5) (см. табл. 8.5) s 2 =
39,27/12 = 3,27 дисперсии а 2 к
; проверим, выполняется ли неравенство (8.4.6) (см. табл. 8.5):

по табл. П. 6.4 при = 3, к 2 = 12 и р = а = 0,05 найдем F 2a = F a = 3,49 . Так как 22,43 > 3,49, неравенство (8.4.6) выполняется. Поэтому гипотезу
Условия и критерии проверки гипотез однофакторного дисперсионного анализа

Н 0: 0 (|) = ... = 0 (4) = 0 отклоняем: считаем, что зафиксированные способы рекламирования продукции влияют на объем продаж; при этом вли-
= 84,9% вариации объема продаж.
Изменим условие задачи. Предположим, что способы рекламирования товара заранее нс фиксированы, а выбраны случайным образом из всего набора способов. Тогда выяснение вопроса о том, влияет или нет способ рекламирования, сводится к проверке гипотезы Н 0: Og = 0 модели М2. Критерий ее проверки такой же, как и в модели Ml. Так как условие (8.4.6) отклонения гипотезы Н 0: о 2 в = 0 выполняется, гипотезу забраковываем, по крайней мере до получения дополнительных данных: считаем, что способ рекламирования товаров (во всем наборе этих способов) влияет на объем продаж.
Двухфакторный дисперсионный анализ
(с одинаковым числом т > 1 наблюдений при различных сочетаниях уровней факторов)
В основе двухфакторного дисперсионного анализа лежит следующая вероятностная модель:
где У/ 1 ’ 7) значение случайной величины У, принимаемое при уровне А (" i = 1,2, ..., v A , фактора А и уровне 5®, у =1,2, ..., v B , фактора В в к -м наблюдении, к = 1,2, ..., /и; 0^, 0 (й у) , 0^д у) - эффекты влияния на У/ 1 ’ соответственно уровней А (" 5® и взаимодействия А (0 и B ; - независимые случайные величины, отражающие влияние на У/ 1 ’ у) неконтролируемых остаточных факторов, причем е?’ л ~ /V((), а л).
Найдем общую вариацию S 2 признака У и ее четыре составляющие - S 2 a , S 2 B , S 2 ab , S 2 r , отражающие влияние соответственно факторов А, В, их взаимодействия и остаточных факторов:

Нетрудно убедится в том, что S 2 = + S 2 B + S 2 iB + S B .
Оценки параметров всех трех типов модели (8.4.9): Ml, М2 и М3, проверяемые гипотезы и критерии их проверки приведены в табл. 8.6. В моделях М2 и М3 предполагается, что все случайные эффекты независимы как между собой, так и с e^’ J) .
) предназначен для сравнения исключительно двух совокупностей. Однако часто он неверно используется для попарного сравнения большего количества групп (рис. 1), что вызывает т.н. эффект множественных сравнений
(англ. multiple comparisons;
Гланц 1999, с. 101-104). Об этом эффекте и о том, как с ним бороться, мы поговорим позднее. В этом же сообщении я опишу принципы однофакторного дисперсионного анализа
, как раз предназначенного для одновременного
сравнения средних значений двух и более групп. Принципы дисперсионного анализа (англ. an
alysis o
f va
riance
, ANOVA) были разработаны в 1920-х гг. сэром Рональдом Эйлмером Фишером (англ. Ronald Aylmer Fisher
) - "гением, едва не в одиночку заложившим основы современной статистики
" (Hald
1998).
Может возникнуть вопрос: почему метод, используемый для сравнения средних значений, называется дисперсионным анализом? Все дело в том, что при установлении разницы между средними значениями мы в действительности сравниваем дисперсии анализируемых совокупностей. Однако обо всем по порядку...
Постановка задачи
Рассмотренный ниже пример заимствован из книги Maindonald & Braun (2010). Имеются данные о весе томатов (все растение целиком; weight , в кг), которые выращивали в течение 2 месяцев при трех разных экспериментальных условиях (trt , от treatment ) - на воде (water ), в среде с добавлением удобрения (nutrient ), а также в среде с добавлением удобрения и гербицида 2,4-D (nutrient+24D ):
# Создадим таблицу с данными: tomato <- data.frame (weight= c (1.5 , 1.9 , 1.3 , 1.5 , 2.4 , 1.5 , # water 1.5 , 1.2 , 1.2 , 2.1 , 2.9 , 1.6 , # nutrient 1.9 , 1.6 , 0.8 , 1.15 , 0.9 , 1.6 ) , # nutrient+24D trt = rep (c ("Water" , "Nutrient" , "Nutrient+24D" ) , c (6 , 6 , 6 ) ) ) # Просмотрим результат: weight weight trt 1 1.50 Water 2 1.90 Water 3 1.30 Water 4 1.50 Water 5 2.40 Water 6 1.50 Water 7 1.50 Nutrient 8 1.20 Nutrient 9 1.20 Nutrient 10 2.10 Nutrient 11 2.90 Nutrient 12 1.60 Nutrient 13 1.90 Nutrient+24D 14 1.60 Nutrient+24D 15 0.80 Nutrient+24D 16 1.15 Nutrient+24D 17 0.90 Nutrient+24D 18 1.60 Nutrient+24D
Переменная trt представляет собой фактор с тремя уровнями. Для более наглядного сравнения экспериментальных условий в последующем, сделаем уровень "water " базовым (англ. reference ), т.е. уровнем, с которым R будет сравнивать все остальные уровни. Это можно сделать при помощи функции relevel() :
Чтобы лучше понять свойства имеющихся данных, визуализируем их при помощи наблюдаемые различия между групповыми средними несущественны и вызваны влиянием случайных факторов
(т.е. в действительности все полученные измерения веса растений происходят из одной нормально распределенной генеральной совокупности):
Подчеркнем еще раз, что рассматриваемый пример соответствует случаю однофакторного дисперсионного анализа: изучается действие одного фактора - условий выращивания (с тремя уровнями - Water , Nutrient и Nutrient+24D ) на интересующую нас переменную-отклик - вес растений.
К сожалению, исследователь почти никогда не имеет возможности изучить всю генеральную совокупность. Как же нам тогда узнать, верна ли приведенная выше нулевая гипотеза, располагая только выборочными данными? Мы можем сформулировать этот вопрос иначе: какова вероятность получить наблюдаемые различия между групповыми средними, извлекая случайные выборки из одной нормально распределенной генеральной совокупности ? Для ответа на этот вопрос на нам потребуется статистический критерий, который количественно характеризовал бы величину различий между сравниваемыми группами.
Чтобы проанализировать изменчивость признака под воздействием контролируемых переменных, применяется дисперсионный метод.
Для изучения связи между значениями – факторный метод. Рассмотрим подробнее аналитические инструменты: факторный, дисперсионный и двухфакторный дисперсионный метод оценки изменчивости.
Дисперсионный анализ в Excel
Условно цель дисперсионного метода можно сформулировать так: вычленить из общей вариативности параметра 3 частные вариативности:
- 1 – определенную действием каждого из изучаемых значений;
- 2 – продиктованную взаимосвязью между исследуемыми значениями;
- 3 – случайную, продиктованную всеми неучтенными обстоятельствами.
В программе Microsoft Excel дисперсионный анализ можно выполнить с помощью инструмента «Анализ данных» (вкладка «Данные» - «Анализ»). Это надстройка табличного процессора. Если надстройка недоступна, нужно открыть «Параметры Excel» и включить настройку для анализа .
Работа начинается с оформления таблицы. Правила:
- В каждом столбце должны быть значения одного исследуемого фактора.
- Столбцы расположить по возрастанию/убыванию величины исследуемого параметра.
Рассмотрим дисперсионный анализ в Excel на примере.
Психолог фирмы проанализировал с помощью специальной методики стратегии поведения сотрудников в конфликтной ситуации. Предполагается, что на поведение влияет уровень образования (1 – среднее, 2 – среднее специальное, 3 – высшее).
Внесем данные в таблицу Excel:


Значимый параметр залит желтым цветом. Так как Р-Значение между группами больше 1, критерий Фишера нельзя считать значимым. Следовательно, поведение в конфликтной ситуации не зависит от уровня образования.
Факторный анализ в Excel: пример
Факторным называют многомерный анализ взаимосвязей между значениями переменных. С помощью данного метода можно решить важнейшие задачи:
- всесторонне описать измеряемый объект (причем емко, компактно);
- выявить скрытые переменные значения, определяющие наличие линейных статистических корреляций;
- классифицировать переменные (определить взаимосвязи между ними);
- сократить число необходимых переменных.
Рассмотрим на примере проведение факторного анализа. Допустим, нам известны продажи каких-либо товаров за последние 4 месяца. Необходимо проанализировать, какие наименования пользуются спросом, а какие нет.



Теперь наглядно видно, продажи какого товара дают основной рост.
Двухфакторный дисперсионный анализ в Excel
Показывает, как влияет два фактора на изменение значения случайной величины. Рассмотрим двухфакторный дисперсионный анализ в Excel на примере.
Задача. Группе мужчин и женщин предъявляли звук разной громкости: 1 – 10 дБ, 2 – 30 дБ, 3 – 50 дБ. Время ответа фиксировали в миллисекундах. Необходимо определить, влияет ли пол на реакцию; влияет ли громкость на реакцию.